

Detailed explanation with examples

Covariance and correlation are widely-used measures in the field of statistics, and thus both are very important concepts in data science. Covariance and correlation provide insight about the ralationship between random variables or features in a dataset. Although these two concepts are highly related, we need to interpret them carefully not to cause any misunderstandings.
Covariance
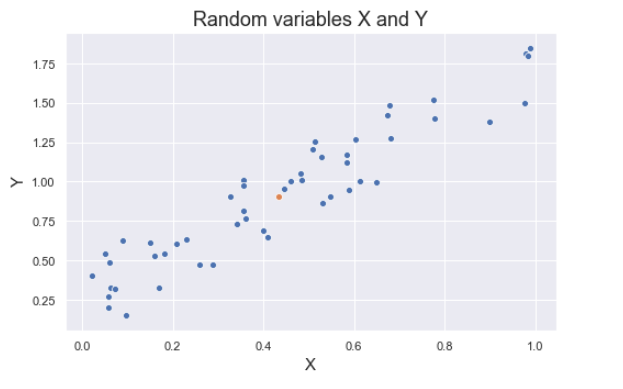
Covariance is a quantitative measure that represents how much the variations of two variables match each other. To be more specific, covariance compares two variables in terms of the deviations from their mean (or expected) value. Consider the random variables “X” and “Y”. Some realizations of these variables are shown in the figure below. The orange dot show the mean of X and mean of Y. As the values of a get away from the mean of X in positive direction, the values of Y tend to change in similar way. Same relation is valid for negative direction as well.
The formula for covariance of two random variables:

where E means the expectation and µ is the mean.
If X and Y change in the same direction, as in the figure above, covariance is positive. Let’s confirm with the covariance function of numpy:

np.cov() returns the covariance matrix. The covariance of X and Y is 0.11. The value at position [0,0] shows the covariance of X with itself and the value at [1,1] shows the covariance of Y with itself. If you run the code np.cov(X,X), you will get the value at position [0,0] which is 0.07707877 in this case. Similarly, np.cov(Y,Y) will return the value at position [1,1].
The covariance of a variable with itself is actually indicates the variance of that variable:
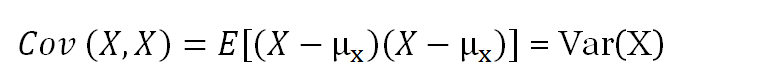
Let’s go over another example. The figure below shows some realizations of random variables Z and T. As we can see, as T increases, Z tends to decrease. Thus, the covariance of Z and T should be negative:


We may also see variables that the variations are independent of each other. For example, in the figure below, realizations of variables A and B seems changing randomly with respect to each other. In this case, we expect to see a covariance value that is close to zero. Let’s confirm:


The following example will provide a little more intuition about the calculation of covariance.

Covariance describes how similarly two random variables deviate from their mean. The red lines show the means of series. The mean of s1 is the vertical line (x=8.5) and the mean of s2 is the horizontol line (y=9.3). Deviation from the mean is the difference between the values and the mean. Covariance is proportional to the product of deviation of s1 and s2 values. Consider the upper right rectangle in the plot above. Both s1 and s2 values are higher than the mean of s1 and s2, respectively. So, deviations are positive. When we multiply two positive values, we get a positive value. In the lower left rectangle, s1 and s2 values are lower than the mean of s1 and s2, respectively. Thus, deviations are negative but we get a positive number when two negative numbers are multiplied. For the points in lower right and upper left rectangle areas, deviations of s1 is positive when the deviation of s2 is negative and vice versa. So we get a negative number when two deviations are multiplied. All the deviations are combined to get the covariance. Hence, if we have more points in negative regions than positive regions, we will get a negative covariance.
Correlation
Correlation is a normalization of covariance by the standard deviation of each variable.

where σ is the standard deviation.
This normalization cancels out the units and the correlation value is always between 0 and 1. Please note that this is the absolute value. In case of a negative correlation between two variables, the correlation is between 0 and -1. If we are comparing the relationship among three or more variables, it is better to use correlation because the value ranges or unit may cause false assumptions.
Consider the dataframe below:

We want to measure the relationship between X-Y and X-Z. We want to find out which variable (Y or Z) is more correlated with X. Let’s use covariance first:

Covariance of X and Z is much higher than the covariance of X and Y. We may think the relationship between the deviations in X and Z is much stronger than that of X and Y. However, it is not the case. Covariance of X and Z is higher because of the value ranges. The range of Z values are in between 22 and 222 whereas the values of Y are around 1 (most of them are less than 1). Therefore, we need to use correlation to eliminate the effect of different value ranges.
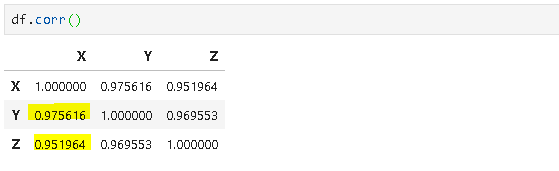
As we can see from the correlation matrix, X and Y are actually more correlated than X and Z.
