


SQL window functions are great tools for data analysis. What they basically do is to perform a calculation across a group of rows that are somehow related.
Consider we have a table that contains a list of employees along with their department and salary. In order to calculate the average employee salary, we can just take the average of the salary column.
What if we want to see the average of each department separately? One option is applying a GROUP BY operation and then taking the average. In this case, the output is a list of all the departments and associated average salaries.
In the output of this scenario, we lose some information because all the rows that belong to a particular group are represented in a single row. We also do not have any other information stored in other columns.
We can always join the output of the GROUP BY operation to the original table. However, there is a better option. The window functions save us from doing this unnecessary extra work.
If we do the above calculation using a window function, each row will contain the relevant average salary information in a separate column. Let’s start with doing an example with both methods to show the difference more clearly.
I prepared a sample table filled with mock data.
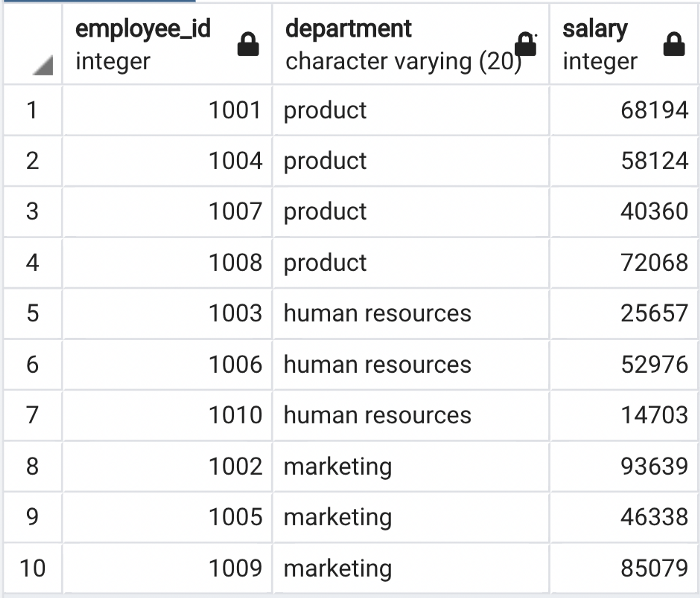
The employees table contains 10 rows and 3 columns. We can calculate the average employee salary in each department as below:
SELECT
department,
AVG(salary) AS avg_salary
FROM employees
GROUP BY department

Here is how we calculate the average department salary with a window function:
SELECT
employee_id,
department,
AVG(salary) OVER (PARTITION BY department) AS avg_salary
FROM employees
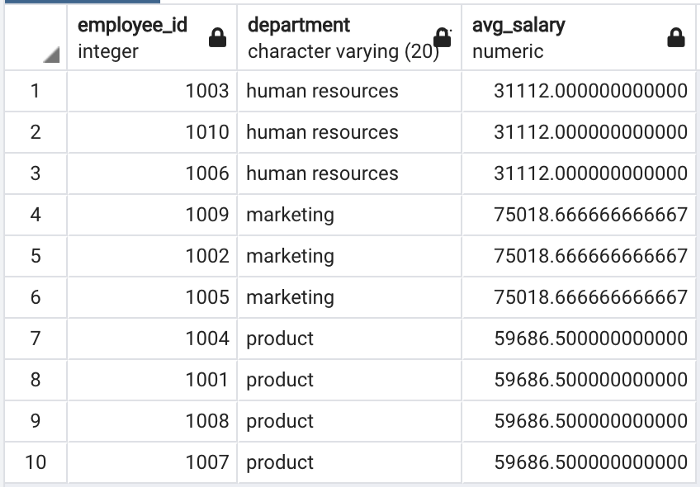
The two examples above demonstrate the difference between the GROUP BY operation and window functions.
The window functions are frequently used for ranking as well. For instance, we can assign a rank to each department based on salaries:
SELECT
employee_id,
department,
salary,
RANK() OVER (PARTITION BY department ORDER BY salary DESC) AS
salary_rank
FROM employees

The rank of the employee with the highest salary within each group is 1.
After an introduction to SQL window functions, we can start on the main topic of this article: Performing these operations with Pandas.
Pandas is a data analysis and manipulation library for Python. Thanks to its highly practical functions and methods, Pandas is one of the most popular libraries in the data science ecosystem.
SQL window functions can easily be replicated with Pandas. Let’s start with the first example where we calculated the average employee salary for each department.
The first step is to import Pandas and create a DataFrame by reading the employees CSV file.
import pandas as pdemployees = pd.read_csv("Downloads/employees.csv")employees.head()

We can calculate the average salary by department as follows:
employees["avg_salary"] = employees.groupby("department")["salary"].transform("mean")
What the above code does is:
- Group the rows based on the department
- Calculate the average salary value of the rows in each group
- Create an avg_salary column with the calculated average values
You may have noticed that we call the mean function using the transform function. If we apply the mean function directly, the output will not have the same shape as the current DataFrame so it cannot be used for creating a new column. The transform function produces an output with the same axis shape as the DataFrame. This is valid for all aggregations used within a “group by” operation.
Here is the employees DataFrame after this operation:

We can do the rank example similarly:
employees["salary_rank"] = employees.groupby("department")["salary"].rank(ascending=False)employees

The rank function assigns the rank in ascending order by default. In order to make the highest one rank first, we need to change the value of the ascending parameter to False.
The other SQL window functions can be replicated with Pandas as well. The logic is the same, only the name of the function changes. For instance, LEAD and LAG are commonly used SQL window functions as well. They are used for getting the values from the next or previous rows, respectively. We can perform the same operation with Pandas by using the shift function.
.
87
1
