


An attempt to explain covariance and correlation in the simplest form.

Analyzing and visualizing variables one at a time is not enough. To make various conclusions and analyses when performing exploratory data analysis, we need to understand how the variables in a dataset interact with respect to each other. There are numerous ways to analyze this relationship visually, one of the most common methods is the use of popular scatterplots. But scatterplots come with certain limitations which we will see in the later sections. Quantitatively, covariance and correlations are used to define the relationship between variables.
Scatterplots
A scatterplot is one of the most common visual forms when it comes to comprehending the relationship between variables at a glance. In the simplest form, this is nothing but a plot of Variable A against Variable B: either one being plotted on the x-axis and the remaining one on the y-axis
%matplotlib inline
import matplotlib.pyplot as plt
plt.style.use('seaborn-whitegrid')
import numpy as npdf = pd.read_csv('weight-height.csv')
df.head()plt.plot(df.Height, df.Weight,'o',markersize=2, color='brown')
plt.xlabel('Height')
plt.ylabel('Weight')
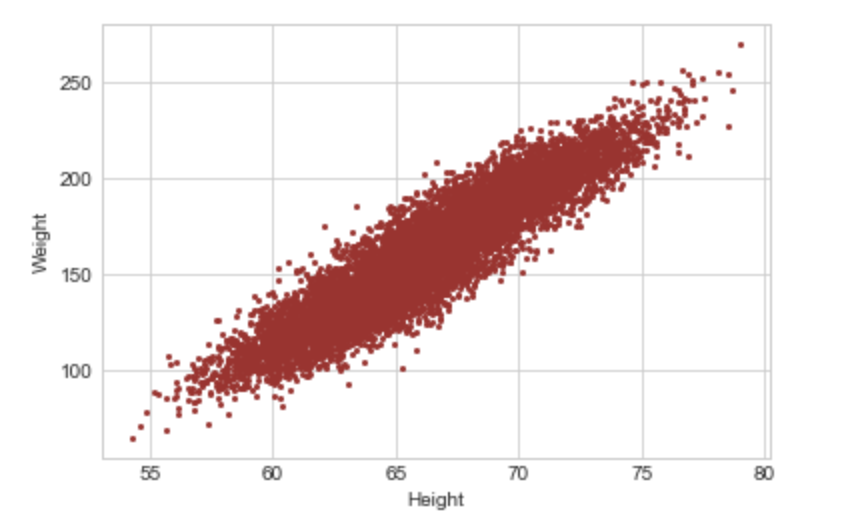
In the above graph, it’s easy to see that there seems to be a positive relationship between the two variables i.e. as one increases the other increases as well. A scatterplot with a negative relationship i.e. as one variable increases the other reduces may take the form of Image 2.
#Just for demonstration purposes I have taken 'a' and 'b'
import numpy as np
import random
import matplotlib.pyplot as plt
a = np.random.rand(100)*70
b = 100-a
plt.plot(a, b,'o',markersize=2, color='brown')
plt.xlabel('a')
plt.ylabel('b')

A scatterplot with no apparent relationship between the two variables would take the form of Image 3:
import numpy as np
import random
import matplotlib.pyplot as plt
a = np.random.rand(1000)*70
b = np.random.rand(1000)*100
plt.plot(a, b,'o',markersize=2, color='brown')
plt.xlabel('a')
plt.ylabel('b')

In general, scatterplots are best for analyzing two continuous variables. Visualizing two discrete variables using a scatterplot may cause the data points to overlap. Let’s see how a scatterplot would look like in the case of discrete variables.
x = [1,1,1,1,2,2,2,2,3,3,3,3]
y = [10,15,15,15,16,16,20,20,20,25,25,25]plt.plot(x,y,'o',markersize=5, color='brown')
plt.xlabel('X')
plt.ylabel('Y')

In the above image, not all points are visible. To overcome this, we add random noise to the data called “Jitter”. The process is naturally called jittering to allow for a somewhat clear visualization of those overlapped points.
def Jitter(values, jitter):
n = len(values)
return np.random.uniform(-jitter, +jitter, n) + values
y1 = Jitter(y,0.9)
plt.plot(x,y1,'o',markersize=4, color='brown')
plt.xlabel('X')
plt.ylabel('Y1')

As seen in Image 5, more data points are now visible. However, jitter should be used only for visualization purposes and should be avoided for analysis purposes.
There can be an overlap of data in the case of continuous variables as well, where overlapping points can hide in the dense part of the data and outliers may be given disproportionate emphasis as seen in Image 1. This is called Saturation.
Scatterplot comes with its own disadvantages as it doesn’t provide quantitative measurement about the relationship, and simply shows the expression of quantitative change. We also can’t use scatterplots to display the relationship between more than two variables. Covariance and Correlation solve both these problems.
Covariance
Covariance measures how variables vary together. A positive covariance means that the variables vary together in the same direction, a negative covariance means they vary in the opposite direction and 0 covariance means that the variables don’t vary together or they are independent of each other. In other words, if there are two variables X & Y, positive covariance means a larger value of X implies a larger value of Y and negative covariance means a larger value of X implies a smaller value of Y.
Mathematically, Cov(x,y) is given by the following formula, where dxi = xi-xmean and dyi = yi -ymean. Note that the following is the formula for the covariance of a population, when calculating covariance of a sample 1/n is replaced by 1/(n-1). Why is it so, is beyond the scope of this article.
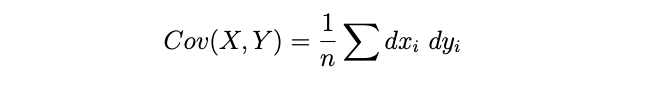
Let’s understand this with an example:
Consider,
x = [34,56,78,23]
y = [20,45,91,16]
=> xmean = 47.75
=> ymean = 43
=> Sum of (dxi*dyi) = (34–47.75)*(20–43) + (56–47.75)*(45–43) + (78–47.75)*(91–43) + (23–47.75)*(16–43) = 2453.
=> Cov(x,y) = 2453/4 = 613.25
In the above example, we can clearly see that as x increases, y increases too and hence we get a positive covariance. Now, let’s consider that x and y have units. x is height in ‘cm’ and y is weight in ‘lbs’. The unit for covariance would then be cm-lbs. Whatever that means!
Covariance can practically take any number which can be overcome using correlation which is in the range of -1 to 1. So covariance doesn’t exactly tell how strong the relationship is but simply the direction of the relationship. For these reasons, it’s also difficult to interpret covariance. To overcome some of these disadvantages we use Correlation.
Correlation
Correlation again provides quantitive information regarding the relationship between variables. Measuring correlation can be challenging if the variables have different units or if the data distributions of the variables are different from each other. Two methods of calculating correlation can help with these issues: 1) Pearson Correlation 2) Spearman Rank Correlation.
Both these methods of calculating correlation involve transforming the data in the variables being compared to some standard comparable format. Let’s see what transformations are done in both these methods.
Pearson Correlation
Pearson correlation involves transforming each of the values in the variables to a standard score or Z score i.e. finding the number of standard deviations away from each of the values is from the mean and calculating the sum of the corresponding products of the standard scores.
Z score = (Xi-Xmean)/Sigma, where sigma implies standard deviation
Suppose we have 2 variables 'x' and 'y'
Z score of x i.e. Zx = (x-xmu)/Sx
Where xmu is the mean, Sx is standard deviation
Translating this info to our understanding of Pearson Correlation (p):
=> pi = Zxi*Zyi
=> pi = ((xi-xmean)*(yi-ymean))/Sx*Sy
=> p = mean of pi values
=> p = (sum of all values of pi)/n
=> p = (summation (xi-xmean)*(yi-ymean))/Sx*Sy*n
As seen above: (summation (xi-xmean)*(yi-ymean))/n is actually Cov(x,y).
So we can rewrite Pearson correlation (p) as Cov(x,y)/Sx*Sy
NOTE: Here, pi is not the same as mathematical constant Pi (22/7)

Pearson correlation ‘p’ will always be in the range of -1 to 1. A positive value of ‘p’ means as ‘x’ increases ‘y’ increases too, negative means as ‘x’ increases ‘y’ decreases and 0 means there is no apparent linear relationship between ‘x’ and ‘y’. Note that a zero Pearson correlation doesn’t imply ‘no relationship’, it simply means that there isn’t a linear relationship between ‘x’ and ‘y’.
Pearson correlation ‘p’ = 1 means a perfect positive relationship, however, a value of 0.5 or 0.4 implies there is a positive relationship but the relationship may not be as strong. The magnitude or the value of Pearson correlation determines the strength of the relationship.
But again, Pearson correlation does come with certain disadvantages. This method of correlation doesn’t work well if there are outliers in the data, as it can get affected by the outliers. Pearson Correlation works well if the changes in variable x with respect to variable y is linear i.e. when the change happens at a constant rate and when x and y are both somewhat normally distributed or when the data is on an interval scale.
These disadvantages of Pearson correlation can be overcome using the Spearman Rank Correlation.
Spearman Rank Correlation
In the Spearman method, we transform each of the values in both variables to its corresponding rank in the given variable and then calculate the Pearson correlation of the ranks.
Consider x = [23,98,56,1,0,56,1999,12],
Corresponding Rankx = [4,7,5,2,1,6,8,3]
Similarly, for y = [5,92,88,45,2,54,90,1],
Corresponding Ranky = [3,8,6,4,2,5,7,1]
Looking at Rankx and Ranky, the advantage of this method seems to be apparent. Both Rankx and Ranky do not contain any outliers, even if the actual data has any outliers, the outlier will be converted into a rank that is nothing but the relative positive of the number in the dataset. Hence, this method is robust against outliers. This method also solves the problem of data distributions. The data distributions of the ranks will always be uniform. We then calculate the Pearson correlation of Rankx and Ranky using the formula seen in the Pearson correlation section.
But Spearman Rank method works well:
- When x changes as y does, but not necessarily at a constant rate i.e. when there is a non-linear relationship between x and y
- When x and y have different data distributions or non-normal distribution
- If you want to avoid the effect of outliers
- When data is on an ordinal scale
