Exploratory Data Analysis(EDA) is the process of understanding and studying the data in detail to discover patterns, spot anomalies and outliers to maximize the insights we derive from the data set. We use data visualization techniques to recognize patterns and draw inferences that are not readily visible in the raw data.
EDA helps in selecting and refining the important features which would be used by machine learning models .
Purpose of EDA
- Gain maximum insight into the dataset
- To identify the various characteristics of data
- Identify missing values and outliers
- List the anomalies in the dataset
- Identify the correlation between variables
Steps in EDA
In order to perform EDA, it’s good to structure your efforts using the below steps.
1.Data Sourcing
- Import and read the data.
2. Data Inspection
- Check for null values, invalid entries, presence of duplicate values
- Summary statistics of the dataset
3. Data Cleaning and manipulation
- Appropriate rows and columns
- Take a call to either Impute or remove missing values using the context of the data set
- Handle Outliers
- Standardize Values
- Data Type conversions
4. Analysis
- Univariate Analysis
- Bivariate Analysis
- Multivariate Analysis
Libraries required to perform EDA
In this writeup, i will be using the below python libraries to perform EDA:
- Numpy — to perform numerical & statistical operations on a data set
- Pandas — makes it incredibly easy to work on large datasets by creating data frames
- Matplotlib & Seaborn to perform data visualization and develop inferences

Data Sourcing
Importing the dataset
Pandas is efficient at storing large data sets. Based on the filetype of your dataset, functions from pandas library can be used to import the dataset.
Some of the commonly used functions in pandas are: read_csv, read_excel, read_xml, read_json
Below is an example to read a csv file using pandas library

Understanding the data
- Check for the shape of the dataset — This gives us a view of the total number of rows and columns.

2. You also need to ensure appropriate data types are loaded into the dataframe. To do so, you can list the various columns in the dataset and their data types using the .info method.
I have passed verbose = True to print the full summary

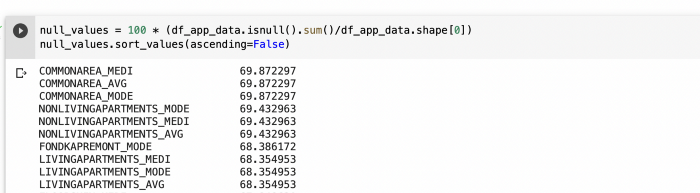
3. Identifying missing values
Large datasets usually have missing values and it’s important to handle these before we proceed with detailed analysis. You can check for the percentage of missing values by summing up all the NULL values ( by using .isnull().sum() ) and dividing it by total rows. I have used .shape and the 0 position in the tuple.
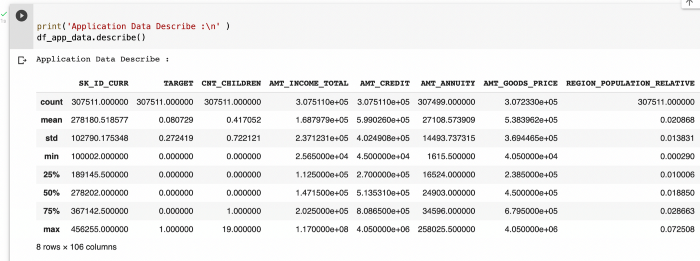
4. Summary Statistics
To get a good sense of the numerical data points, we can use the describe function.
This helps us get a feel for the data by studying values like standard deviation, min,max,mean, quantiles (25, 50,75)
Data Cleaning
1.Dropping Rows/Columns
Columns with large amount of missing values, say more than 40–50% null values, can be dropped

If the missing values for a feature are very low, we can drop rows that contain those missing values.
2. Imputing missing values
Process of estimating the missing values and filling them is called imputation. When the percentage of missing values is relatively low and you can impute the values.
There is no one right way to impute the missing value and you would have to decide based on the context of data, reasonable assumptions and assess the implications of imputing the missing values. Some of the ways you could go about imputing are the following ways:
- For categorical variables, we could impute missing value with the dominant category i.e using the mode

- For numerical variables, we could impute the missing values with mean/Median. Median is preferred when there are outliers in the data set as median would take the middle value of the dataset.

- Sometimes it is also good to just impute the missing values with a label like “Missing” for analysis depending on the percentage of null values in the columns
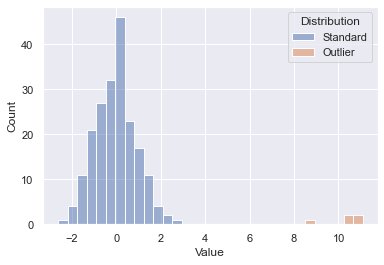
3. Handling Outliers
Outliers are values that are numerically distant from the rest of data points.
Some of the various approaches to handle outliers are:
- Deletion of Outlier values
- Imputing the values
- Binning of values into categories
- Capping the values
- Performing a separate outlier analysis
Below is an example of how to slice the data into bins and create a new column in t the dataframe.

4. Standardizing values
- All the values in a feature should be of a common and consistent unit.
- We could standardize precision. For eg. numerical values could be rounded off to two decimal places.
5. Data Type conversions
All the features should be of correct data type. For eg. numerical values could be stored as strings in the dataset. We would not be able to get the min, max, mean, median etc for strings.

Now that we have cleaned the data, it’s ripe for analysis. This is where the fun begins and we can perform different types of analysis to spot patterns and identify feature we will later on use to build a model
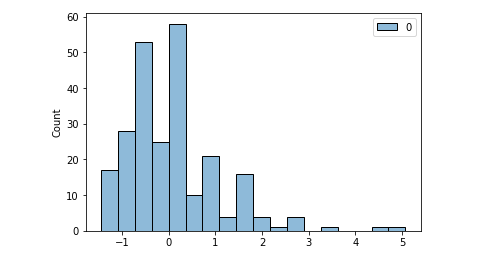
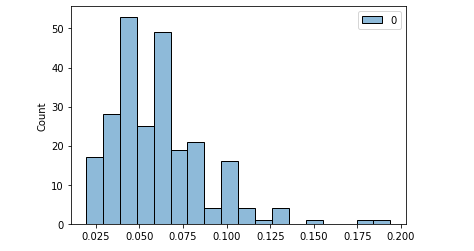
Univariate Analysis
In univariate analysis, we visualize a single variable and get summary statistics
Summary Statistics include:
- Frequency distribution
- Central Tendency — Mean, median, mode, max, min
- Dispersion — variance, standard deviation and range
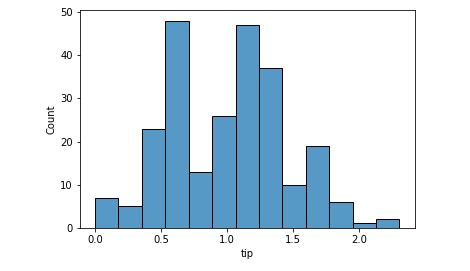
Univariate analysis should be done on both numerical and categorical variables.Plots like bar, pie, hist are useful for univariate analysis.
Pie Chart
Below is an example to create pie chart

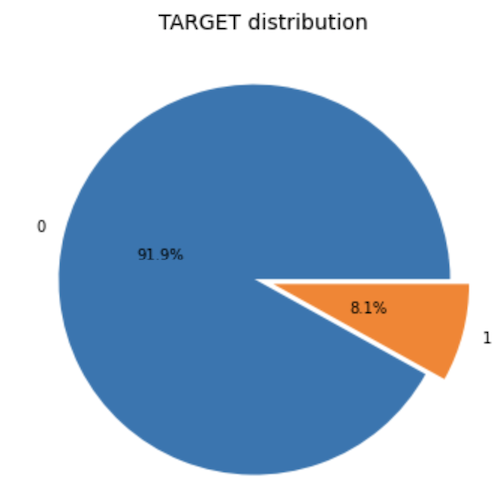
Using functions to perform univariate analysis
To avoid repeated lines of code and save time, I created functions which would perform univariate analysis of categorical and numerical variables.
Below is an example of the function for categorical variables which plots the total percentage of values, percentage of defaulters and non defaulters split by TARGET variable for my case study:

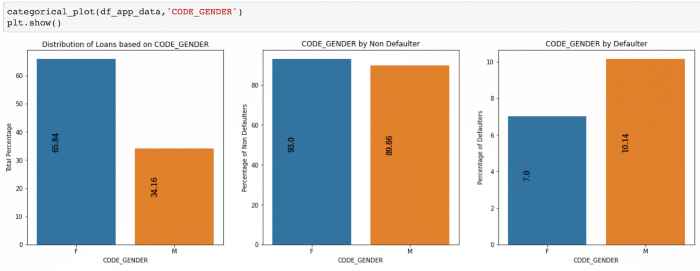
Below is an example of the function for numerical variables


Bivariate and Multivariate Analysis
Bivariate analysis involves analyzing two variables to determine the relationship between them. Using Bivariate analysis, we can determine if there is a correlation between the variables.
Multivariate analysis involves analysis of more than two variables.The goal is to understand which variables influence the outcome and the relationship of variables with each other.
We could use various plots like scatter plot, box plot, heatmap for analysis.
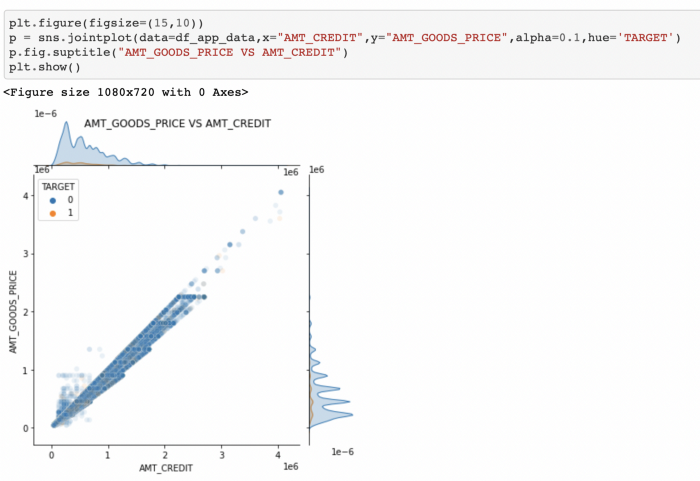
Joint plots
Below is an example of bivariate analysis which shows a positive correlation:
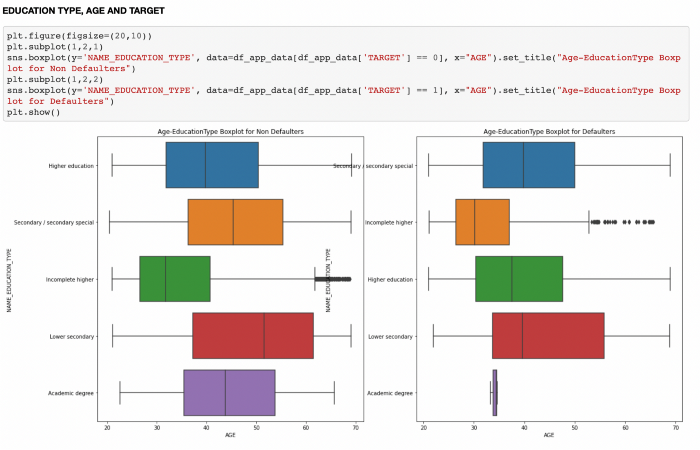
Box and whisker plot
Below is an example of bivariate analysis using boxplot:
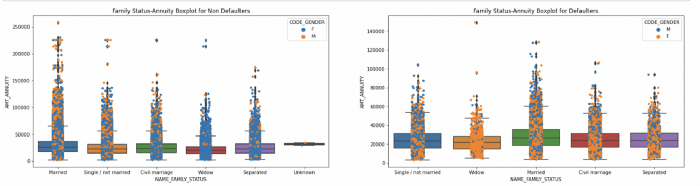
Boxplot used with Stripplot and Hue
Below is an example of multivariate analysis. Here, we segment the data based on various scenarios and draw insights using multivariate analysis.

Heatmaps
Heatmaps are powerful and help visualize how multiple variables in our dataset are correlated.
Correlation coefficients indicates the strength between two variables and its values range from -1 to 1.
1 — indicates strong positive relationship
0 — indicates no relationship
-1 — indicates strong negative relationship
Below is an example of a function which plots a diagonal correlation matrix using heatmaps.



Conclusion:
In this writeup I have explained the various steps for performing Exploratory data analysis using Python code.