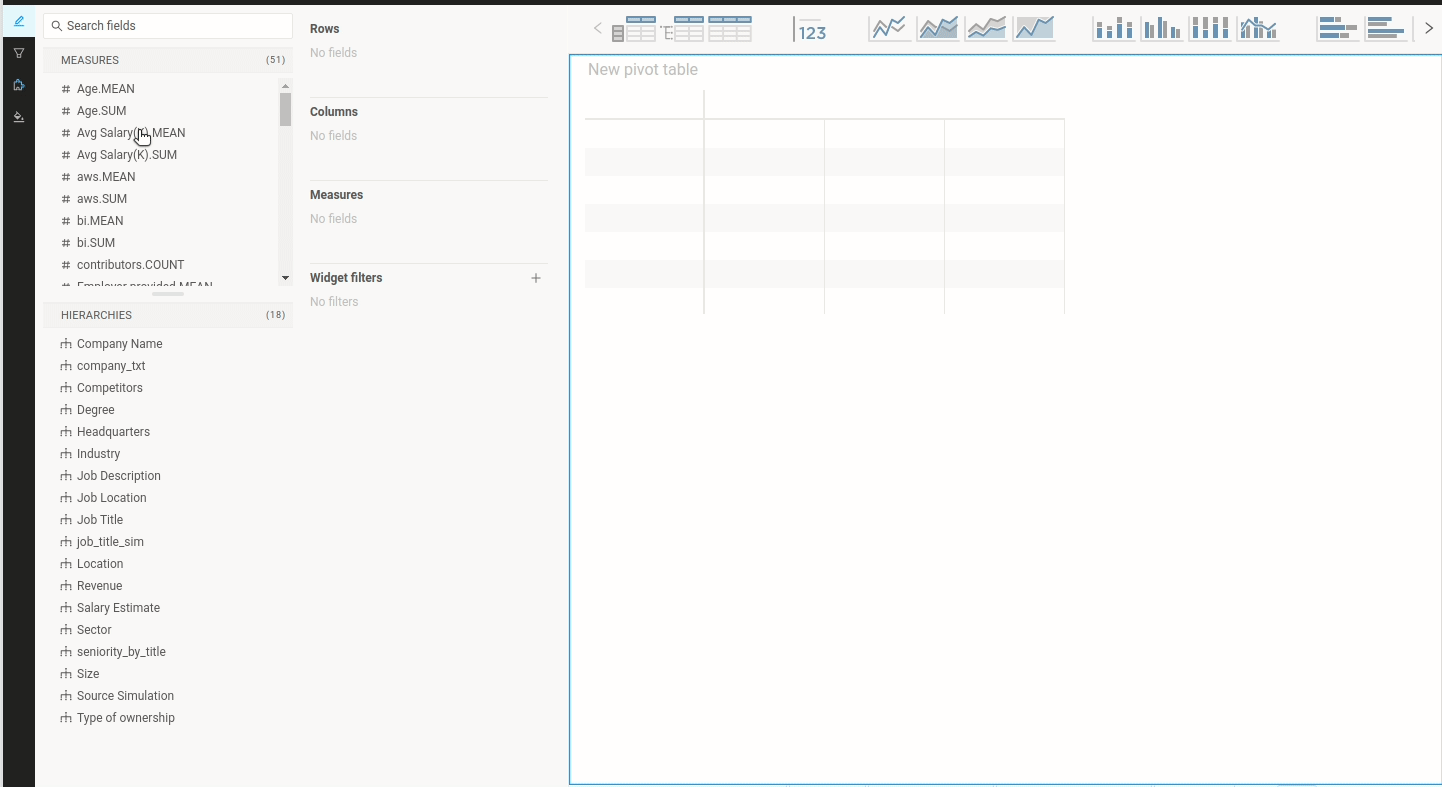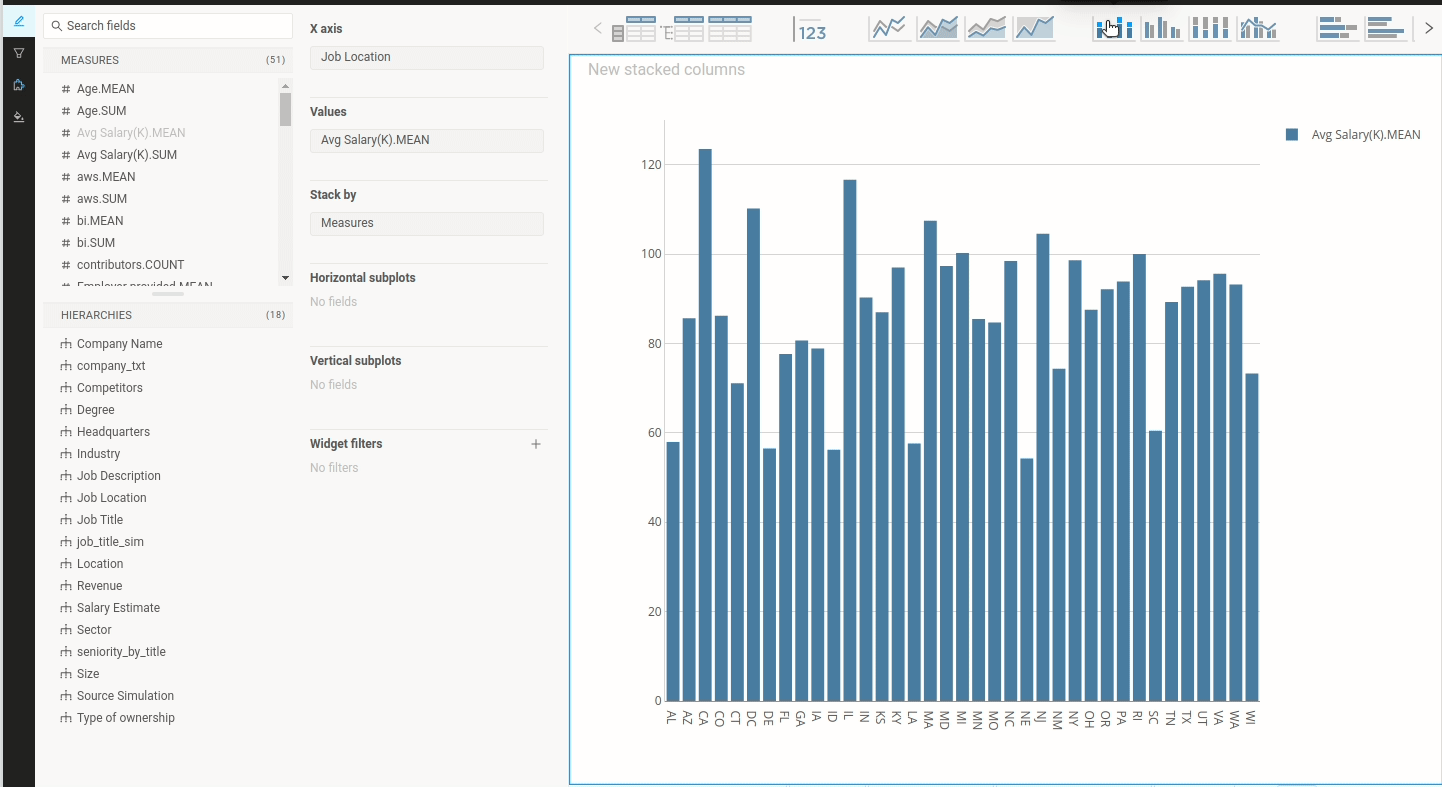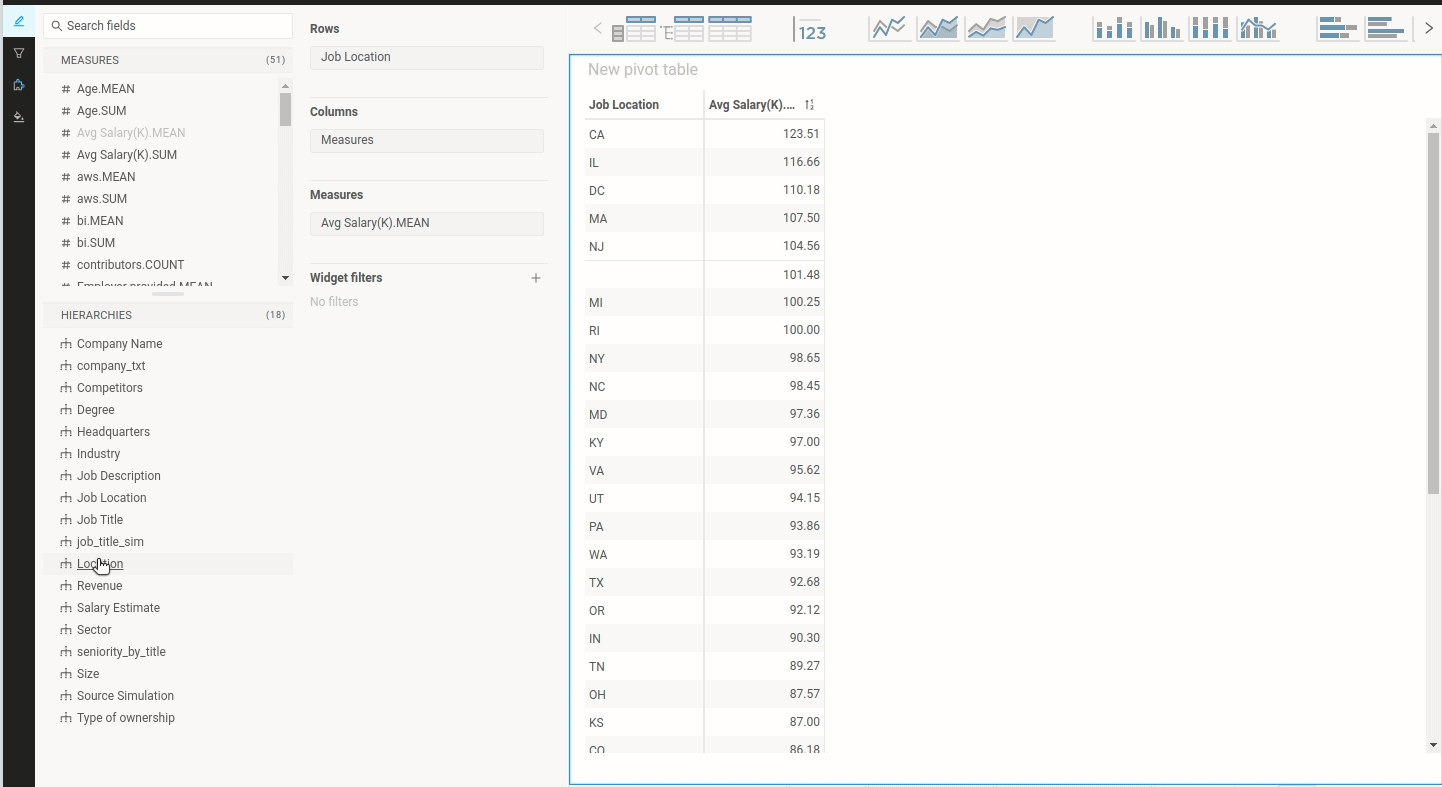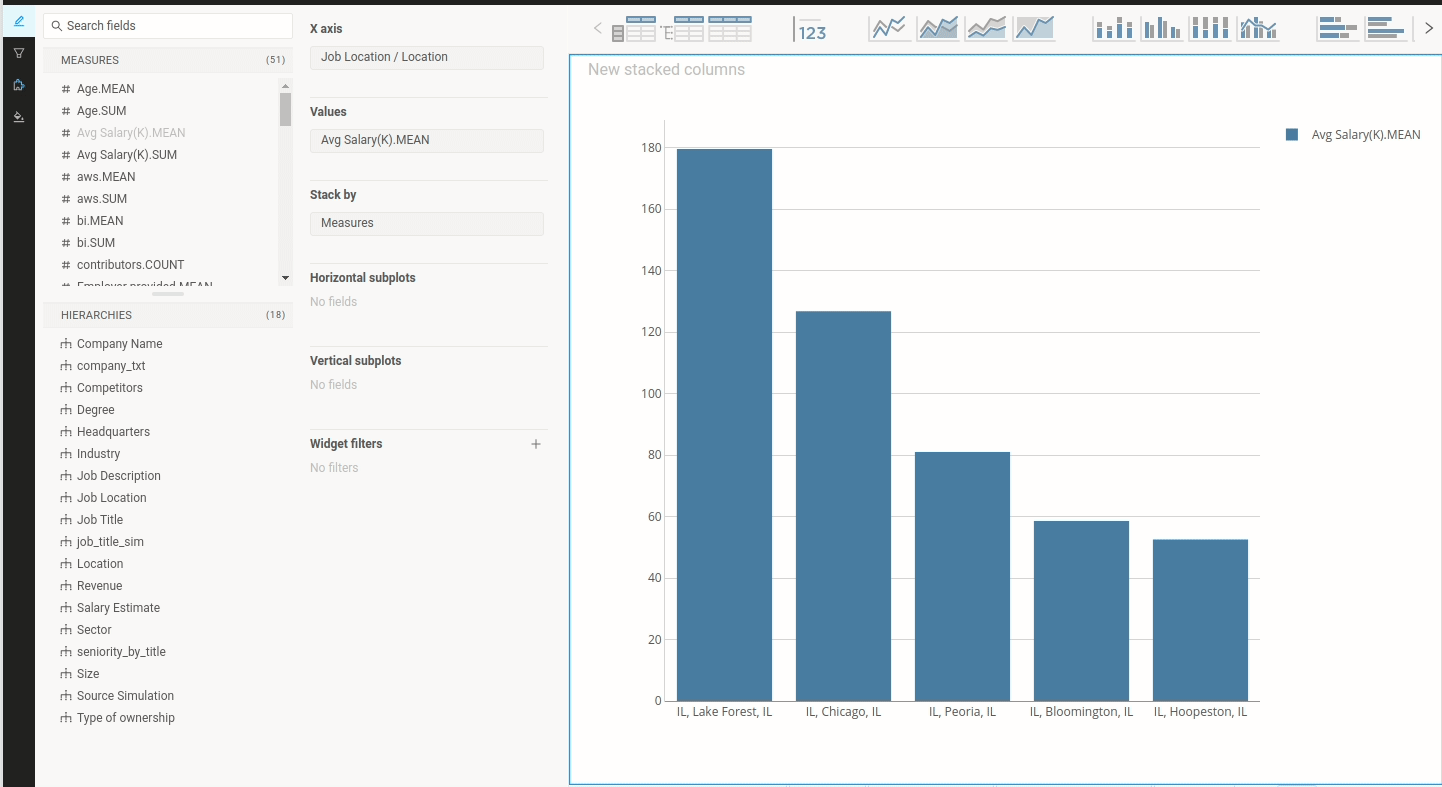
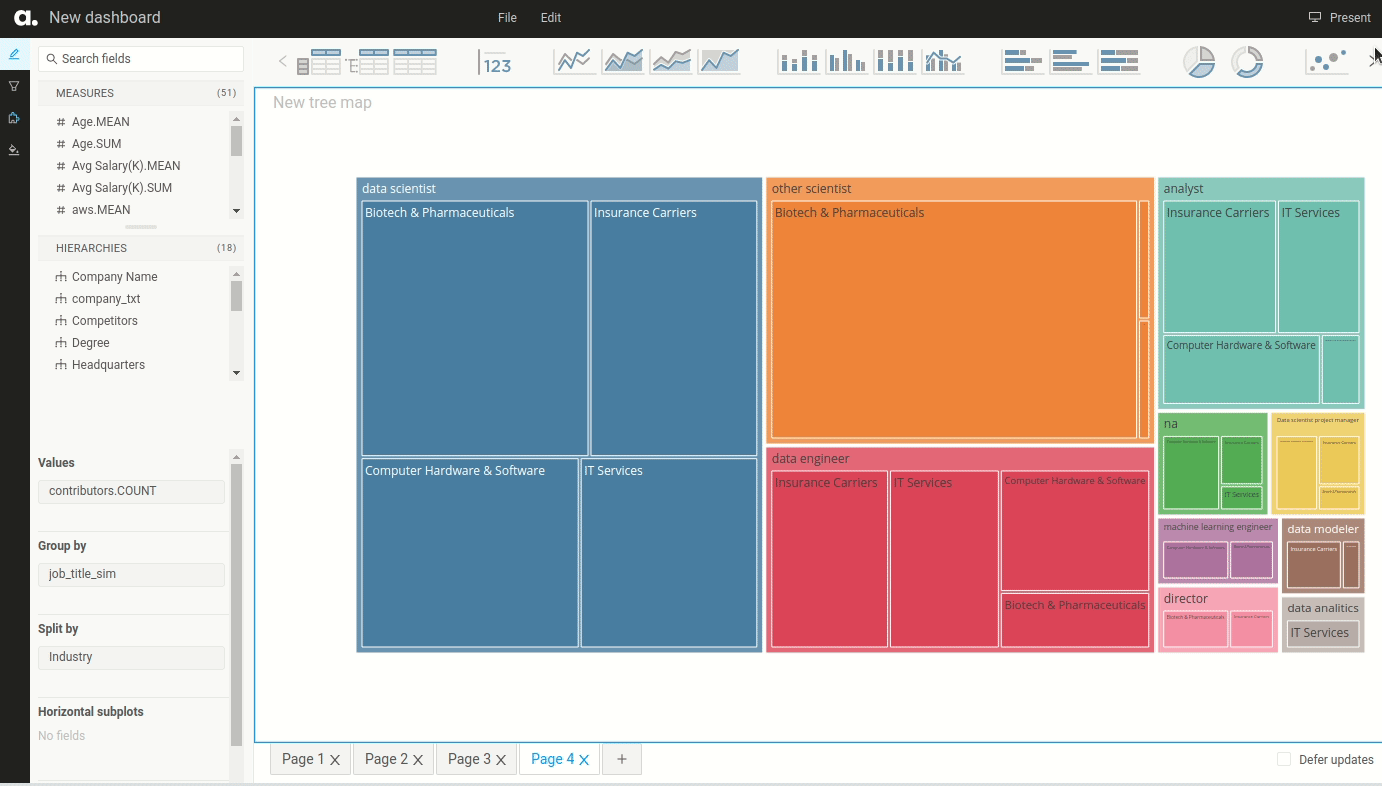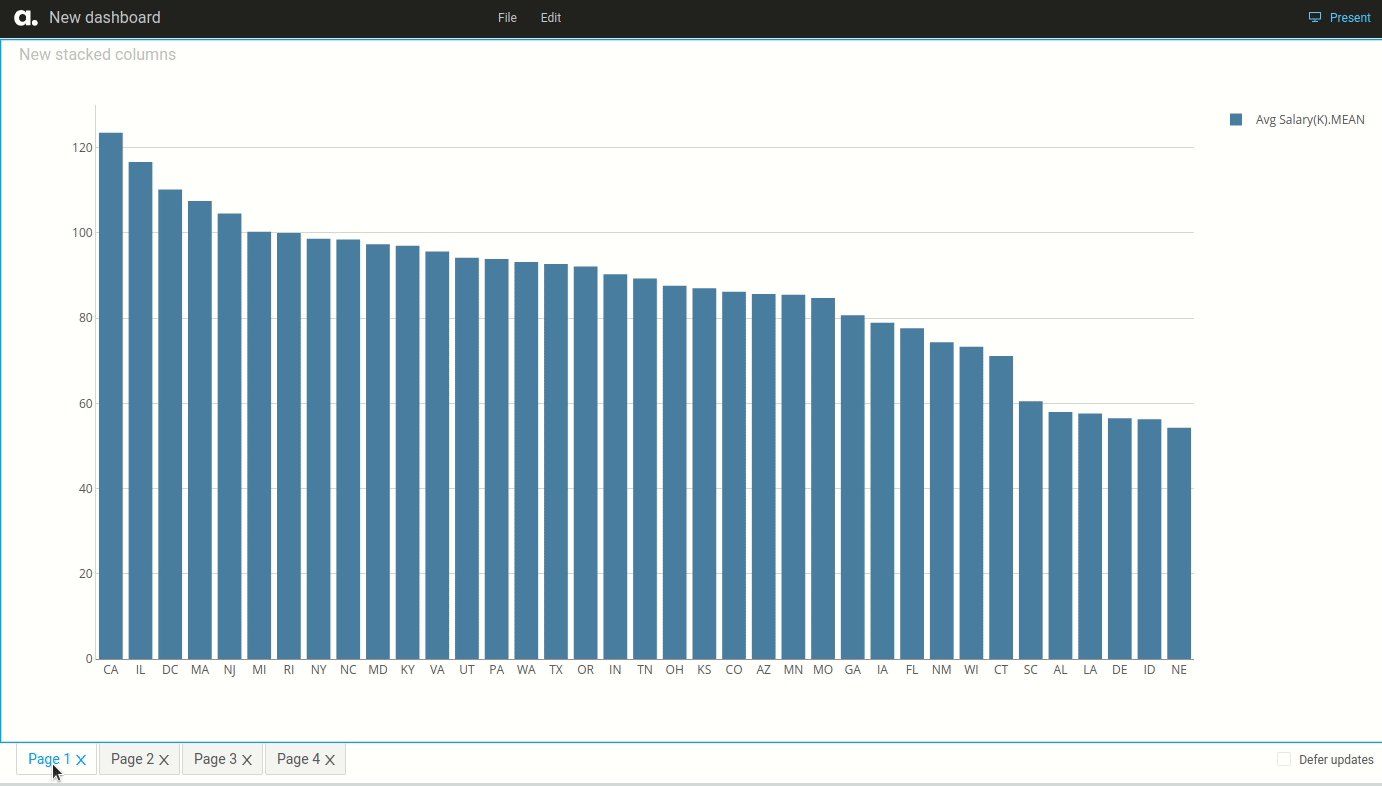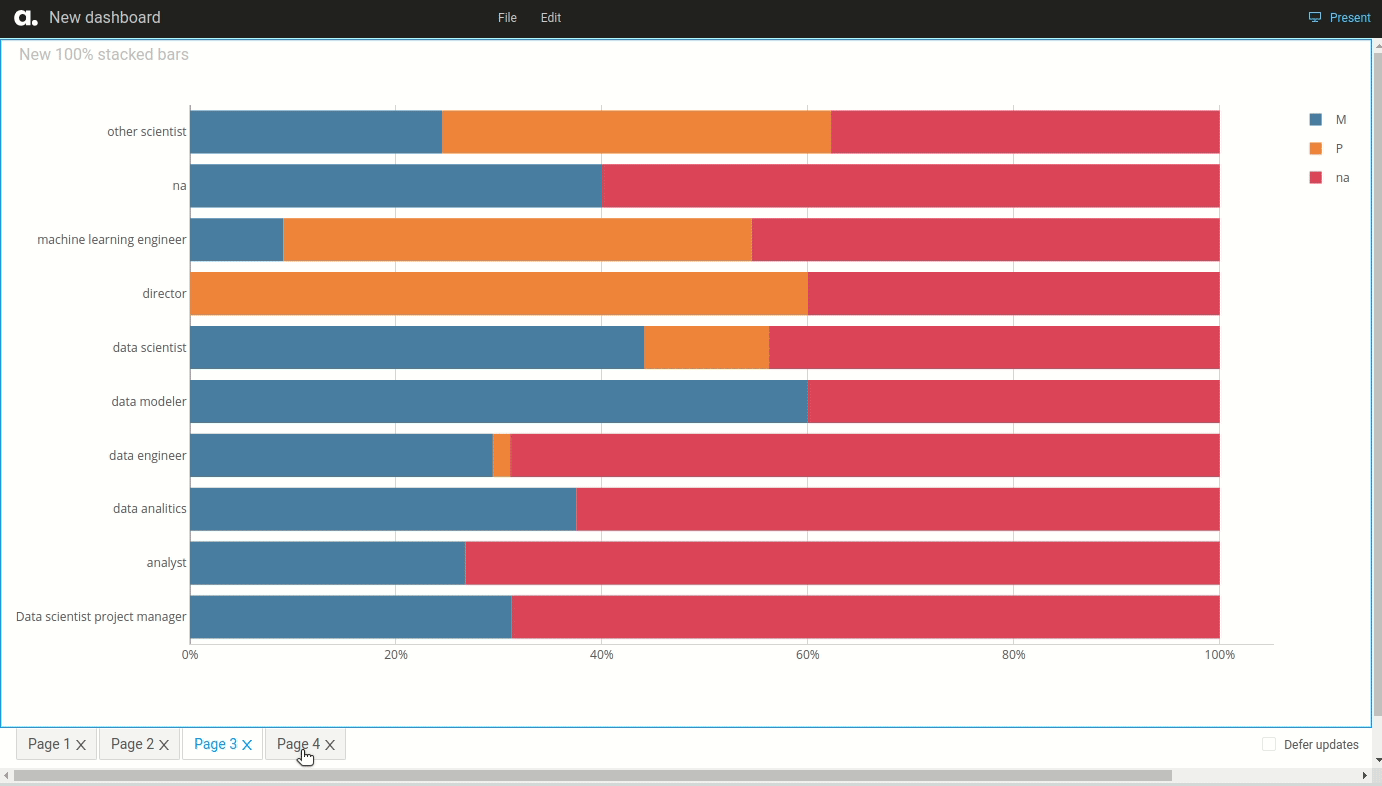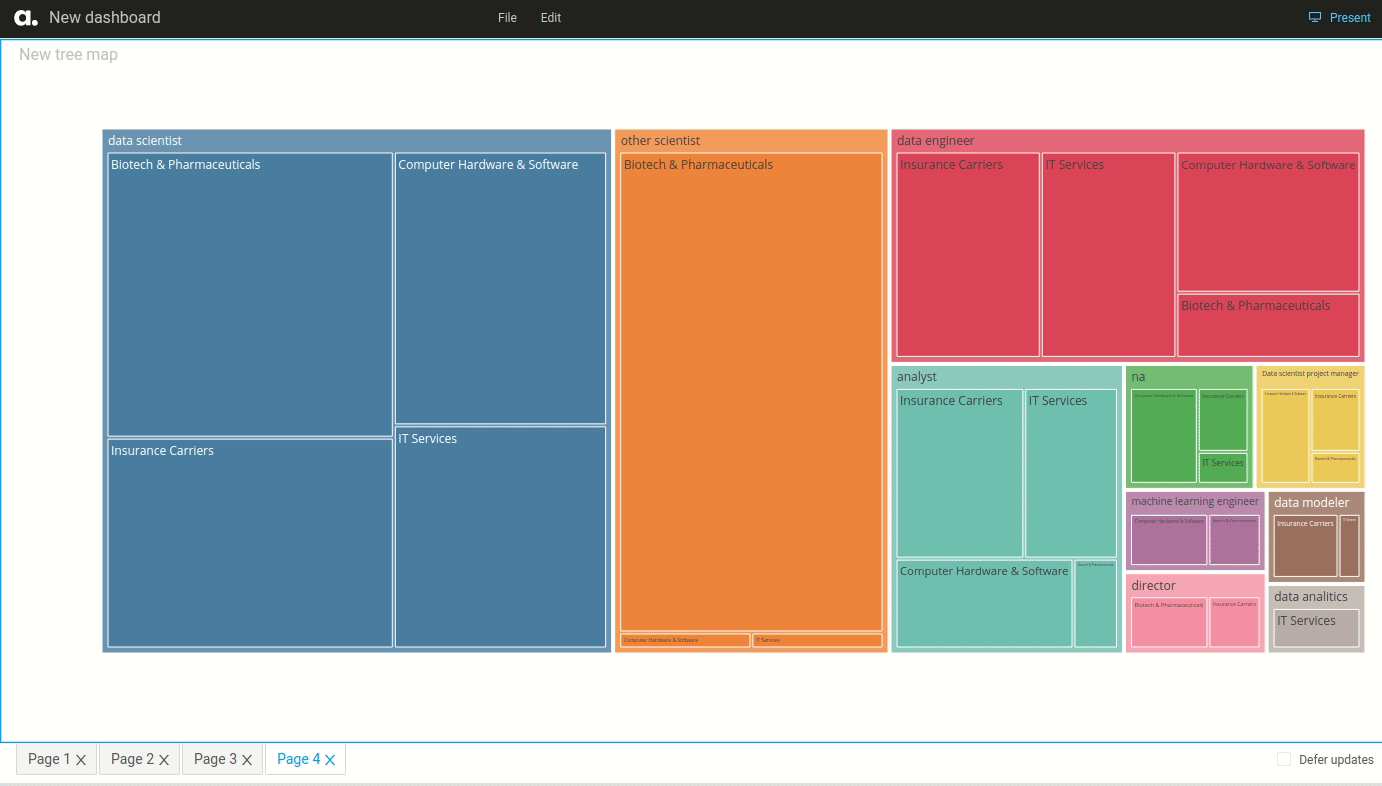
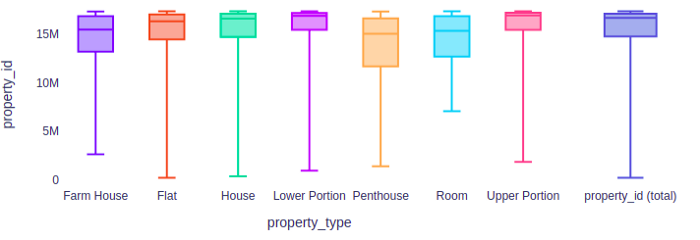
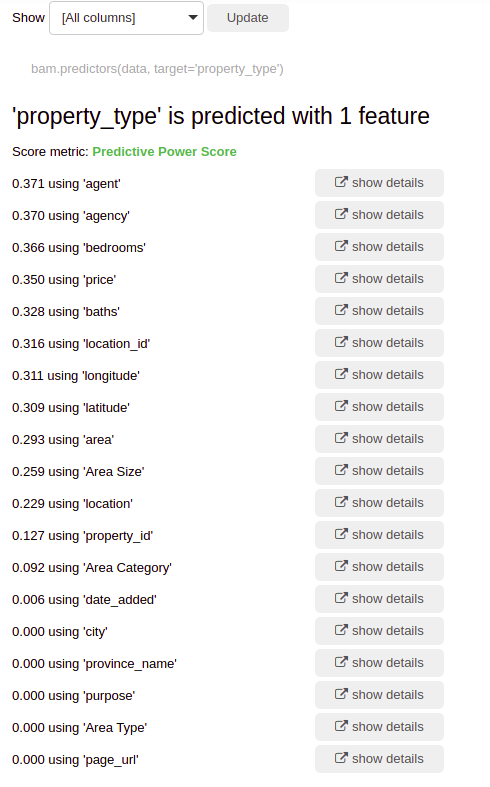
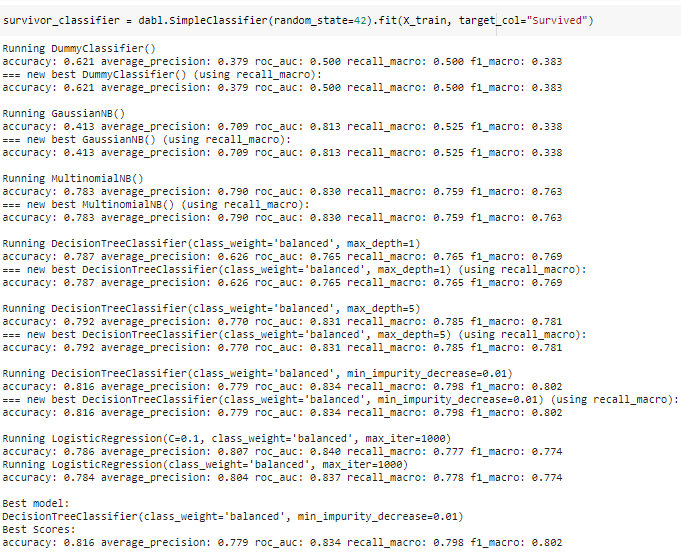
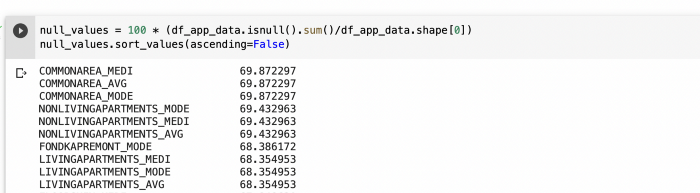
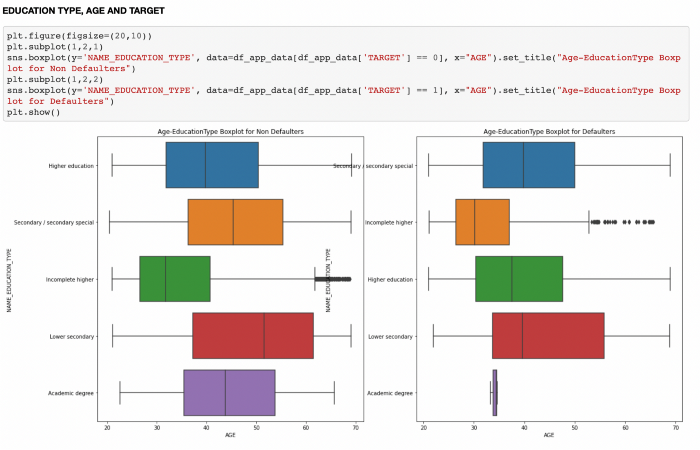
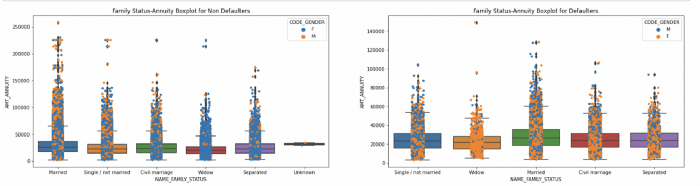
Machine learning is the science of getting computers to act without being explicitly programmed.” — Andrew Ng
Machine learning algorithms are a crucial part of data science, allowing us to make predictions and understand complex data sets. In this guide, we will cover the top 10 machine learning algorithms that every data scientist should know.

1. K-Nearest Neighbors (KNN)
KNN is a simple but powerful classification algorithm that uses data point proximity to determine class membership. It works by identifying the K data points that are closest to the data point in question, and then assigning the data point to the class that is most represented among those K points.
Key features of KNN include:
- Easy to implement and understand
- Can be used for both classification and regression
- Flexible, as the number of nearest neighbors (K) can be adjusted
A real-world example of KNN in action is in credit scoring, where it can be used to predict the likelihood of a loan applicant defaulting on their loan.
2. Decision Trees
Decision trees are a type of supervised learning algorithm that can be used for both classification and regression tasks. They work by creating a tree-like structure that splits the data into smaller and smaller subsets based on certain rules or conditions. The final splits result in predictions or classifications for each data point.
Key features of decision trees include:
- Easy to understand and interpret
- Can handle both numerical and categorical data
- Can handle multiple input features
A real-world example of decision trees in action is in medical diagnosis, where they can be used to determine the most likely cause of a patient’s symptoms based on their medical history and test results.
3. Support Vector Machines (SVMs)
SVMs are a type of supervised learning algorithm that can be used for both classification and regression tasks. They work by finding the hyperplane in a high-dimensional space that maximally separates the different classes. Data points are then classified based on which side of the hyperplane they fall on.
Key features of SVMs include:
- Can handle high-dimensional data
- Effective in cases where there is a clear margin of separation between classes
- Can be kernelized to handle nonlinear boundaries
A real-world example of SVMs in action is in face recognition, where they can be used to classify different faces based on features such as the shape of the eyes and nose.
4. Naive Bayes
Naive Bayes is a simple but powerful classification algorithm that uses the Bayes theorem to make predictions. It assumes that all input features are independent of each other, which makes it “naive” but also allows it to make fast and accurate predictions.
Key features of Naive Bayes include:
- Simple and easy to implement
- Fast and efficient
- Can handle a large number of input features
A real-world example of Naive Bayes in action is in spam detection, where it can be used to classify emails as spam or not based on features such as the sender, subject line, and content of the email.
5. Linear Regression
Linear regression is a simple and commonly used statistical method for modeling the relationship between a dependent variable and one or more independent variables. It assumes that the relationship between the variables is linear, and uses this assumption to make predictions about the dependent variable based on the values of the independent variables.
Key features of linear regression include:
- Simple and easy to implement
- Can handle multiple independent variables
- Can be extended to include regularization to prevent overfitting
A real-world example of linear regression in action is in stock price prediction, where it can be used to model the relationship between a company’s stock price and factors such as its earnings and market conditions.
6. Logistic Regression
Logistic regression is a variation of linear regression that is used for classification tasks. It works by using the same basic assumptions as linear regression, but instead of predicting a continuous output, it predicts the probability that a given input belongs to a certain class.
Key features of logistic regression include:
- Can handle multiple input features
- Can output probabilities, allowing for a more nuanced understanding of the data
- Can be regularized to prevent overfitting
A real-world example of logistic regression in action is in credit scoring, where it can be used to predict the likelihood of a loan applicant defaulting on their loan based on factors such as their credit history and income.
7. Artificial Neural Networks (ANNs)
Artificial neural networks, also known as neural networks or deep learning networks, are a type of machine learning algorithm that is inspired by the structure and function of the human brain. They consist of multiple layers of interconnected “neurons,” which process and transform the input data to produce an output.
Key features of ANNs include:
- Can handle complex, nonlinear relationships between variables
- Can learn and adapt to new data over time
- Can handle a large number of input features
A real-world example of ANNs in action is in image recognition, where they can be used to classify images based on their content.
8. Random Forest
Random forest is an ensemble learning algorithm that uses multiple decision trees to make predictions. It works by training multiple decision trees on random subsets of the data, and then combining their predictions to make a final prediction. This approach can improve the accuracy and stability of the predictions compared to using a single decision tree.
Key features of random forest include:
- Can handle both classification and regression tasks
- Can handle a large number of input features
- Robust to overfitting
A real-world example of random forest in action is in fraud detection, where it can be used to identify suspicious activity in a dataset of financial transactions.
9. Gradient Boosting
Gradient boosting is another ensemble learning algorithm that uses multiple “weak” learners to make predictions. It works by training the weak learners in sequence, with each subsequent learner attempting to correct the errors made by the previous learner. This process continues until a satisfactory prediction is made.
gradient boosting includes:
- Can handle both classification and regression tasks
- Can handle a large number of input features
- Can achieve high accuracy in predictions
A real-world example of gradient boosting in action is in customer churn prediction, where it can be used to identify customers who are likely to stop using a company’s products or services.
10. Clustering
Clustering is a type of unsupervised learning algorithm that is used to group data points into clusters based on their similarity. The algorithm works by dividing the data into clusters such that data points within a cluster are more similar to each other than they are to data points in other clusters.
Key features of clustering include:
- Can handle a large number of input features
- Can identify underlying patterns and structures in the data
- Can be used for data exploration and visualization
A real-world example of clustering in action is in market segmentation, where it can be used to group customers into different segments based on their behavior and characteristics.