

Learn how to present the relationships amongst the features using multivariate charts and plots in Python
While dealing with a big dataset, it is important to understand the relationship between the features. That is a big part of data analysis. The relationships can be between two variables or amongst several variables. I will discuss how to present the relationships between multiple variables with some simple techniques. Python’s Numpy, Pandas, Matplotlib, and Seaborn libraries will be used.
First, import the necessary packages and the dataset to be used.
%matplotlib inline
import matplotlib.pyplot as plt
import seaborn as sns
import pandas as pd
import numpy as np
df = pd.read_csv("nhanes_2015_2016.csv")
This dataset is very large. At least too large to show a screenshot here. Here are the columns in this dataset.
df.columns
#Output:
Index(['SEQN', 'ALQ101', 'ALQ110', 'ALQ130', 'SMQ020', 'RIAGENDR', 'RIDAGEYR', 'RIDRETH1', 'DMDCITZN', 'DMDEDUC2', 'DMDMARTL', 'DMDHHSIZ', 'WTINT2YR', 'SDMVPSU', 'SDMVSTRA', 'INDFMPIR', 'BPXSY1', 'BPXDI1', 'BPXSY2', 'BPXDI2', 'BMXWT', 'BMXHT', 'BMXBMI', 'BMXLEG', 'BMXARML', 'BMXARMC', 'BMXWAIST', 'HIQ210'], dtype='object')
Now, let’s make the dataset smaller with a few columns. So, it’s easier to handle and show in this article.
df = df[['SMQ020', 'RIAGENDR', 'RIDAGEYR','DMDCITZN',
'DMDEDUC2', 'DMDMARTL', 'DMDHHSIZ','SDMVPSU',
'BPXSY1', 'BPXDI1', 'BPXSY2', 'BPXDI2', 'RIDRETH1']]
df.head()

Column names may look strange to you. I will keep explaining as we keep using them.
- In this dataset, we have two systolic blood pressure data (‘BPXSY1’, ‘BPXSY2) and two diastolic blood pressure data (‘BPXDI1’, ‘BPXDI2’). It is worth looking at if there is any relationship between them. Observe the relationship between the first and second systolic blood pressure.
To find out the relation between two variables, scatter plots have been being used for a long time. It is the most popular, basic, and easily understandable way of looking at a relationship between two variables.
sns.regplot(x = "BPXSY1", y="BPXSY2", data=df, fit_reg = False, scatter_kws={"alpha": 0.2})
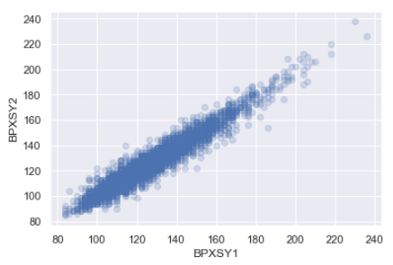
The relationship between the two systolic blood pressures is positively linear. There is a lot of overlapping observed in the plot.
2. To understand the systolic and diastolic blood pressure data and their relationships more, make a joint plot. Jointplot shows the density of the data and the distribution of both the variables at the same time.
sns.jointplot(x = "BPXSY1", y="BPXSY2", data=df, kind = 'kde')

In this plot, it shows very clearly that the densest area is from 115 to 135. Both the first and second systolic blood pressure distribution is right-skewed. Also, both of them have some outliers.
3. Find out if the correlation between the first and second systolic blood pressures are different in the male and female population.
df["RIAGENDRx"] = df.RIAGENDR.replace({1: "Male", 2: "Female"})
sns.FacetGrid(df, col = "RIAGENDRx").map(plt.scatter, "BPXSY1", "BPXSY2", alpha =0.6).add_legend()
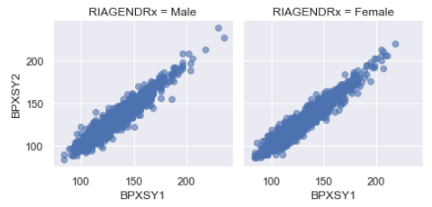
This picture shows, both the correlations are positively linear. Let’s find out the correlation with more clarity.
print(df.loc[df.RIAGENDRx=="Female",["BPXSY1", "BPXSY2"]].dropna().corr())
print(df.loc[df.RIAGENDRx=="Male",["BPXSY1", "BPXSY2"]].dropna().corr())

From the two correlation chart above, the correlation between two systolic blood pressure is 1% higher in the female population than in the male. If these things are new to you, I encourage you to try understanding the correlation between two diastolic blood pressures or systolic and diastolic blood pressures.
4. Human behavior can change with so many different factors such as gender, education level, ethnicity, financial situation, and so on. In this dataset, we have ethnicity (“RIDRETH1”) information as well. Check the effect of both ethnicity and gender on the relationship between both the systolic blood pressures.
sns.FacetGrid(df, col="RIDRETH1", row="RIAGENDRx").map(plt.scatter, "BPXSY1", "BPXSY2", alpha = 0.5).add_legend()
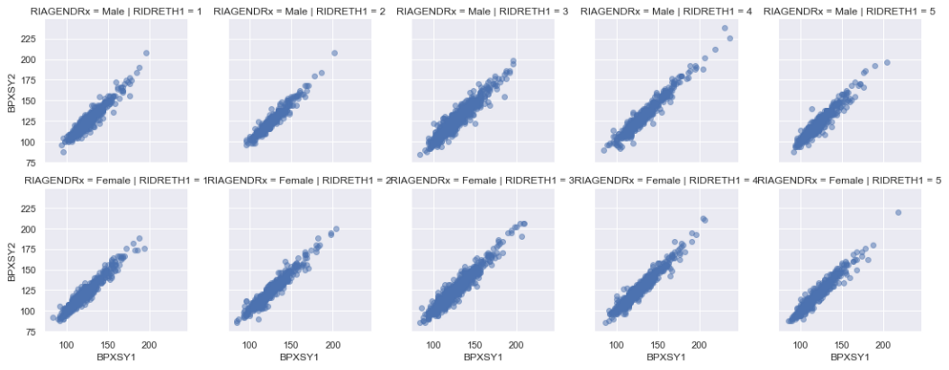
With different ethnic origins and gender, correlations seem to be changing a little bit but generally stays positively linear as before.
5. Now, focus on some other variables in the dataset. Find the relationship between education and marital status.
Both the education column(‘DMDEDUC2’) and the marital status (‘DMDMARTL’) column are categorical. First, replace the numerical values with the string values that will make sense. We also need to get rid of values that do not add good information to the chart. Such as the education column has some values ‘Don’t know’ and the marital status column has some ‘Refused’ values.
df["DMDEDUC2x"] = df.DMDEDUC2.replace({1: "<9", 2: "9-11", 3: "HS/GED", 4: "Some college/AA", 5: "College", 7: "Refused", 9: "Don't know"})df["DMDMARTLx"] = df.DMDMARTL.replace({1: "Married", 2: "Widowed", 3: "Divorced", 4: "Separated", 5: "Never married", 6: "Living w/partner", 77: "Refused"})db = df.loc[(df.DMDEDUC2x != "Don't know") & (df.DMDMARTLx != "Refused"), :]
Finally, we got this DataFrame that is clean and ready for the chart.
x = pd.crosstab(db.DMDEDUC2x, db.DMDMARTLx)
x
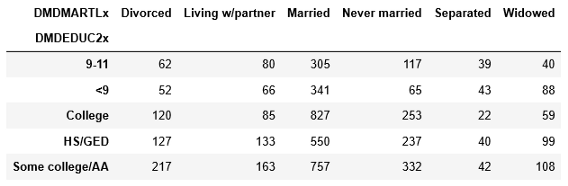
Here is the result. The numbers look very simple to understand. But a chart of population proportions will be a more appropriate presentation. I am getting a population proportion based on marital status.
x.apply(lambda z: z/z.sum(), axis=1)

6. Find the population proportion of marital status segregated by Ethnicity (‘RIDRETH1’) and education level.
First, replace the numeric value with meaningful strings in the ethnicity column. I found these string values from the Center for Disease Control website.
db.groupby(["RIDRETH1x", "DMDEDUC2x", "DMDMARTLx"]).size().unstack().fillna(0).apply(lambda x: x/x.sum(), axis=1)

7. Observe the difference in education level with age.
Here, education level is a categorical variable and age is a continuous variable. A good way of observing the difference in education levels with age will be to make a boxplot.
plt.figure(figsize=(12, 4))
a = sns.boxplot(db.DMDEDUC2x, db.RIDAGEYR)

This plot shows, the rate of a college education is higher in younger people. A violin plot may provide a better picture.
plt.figure(figsize=(12, 4))
a = sns.violinplot(db.DMDEDUC2x, db.RIDAGEYR)

So, the violin plot shows a distribution. The most college-educated people are around age 30. At the same time, most people who are less than 9th grade, are about 68 to 88 years old.
8. Show the marital status distributed by and segregated by gender.
fig, ax = plt.subplots(figsize = (12,4))
ax = sns.violinplot(x= "DMDMARTLx", y="RIDAGEYR", hue="RIAGENDRx", data= db, scale="count", split=True, ax=ax)
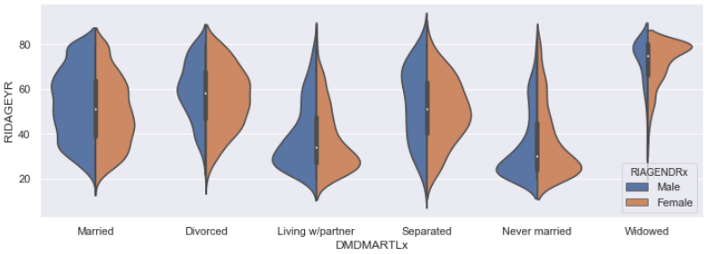
Here, blue color shows the male population distribution and orange color represents the female population distribution. Only ‘never married’ and ‘living with partner’categories have similar distributions for the male and female populations. Every other category has a notable difference in the male and female populations.
