This is the second part in Machine Learning series where we discuss on Features handling before using the data for machine learning models. The articles contains below parts:
- Feature representation
- Feature selection
- Feature transformation
- Feature engineering
This article cover the basic concepts of modifying the features as data needs to be refined before it can be used for prediction. We need to remove garbage out of data and turn features into high quality features.
Feature Representation
Your features need be represented as quantitative (preferably numeric) attributes of the thing you’re sampling. They can be real world values, such as the readings from a sensor, and other discernible, physical properties. Alternatively, your features can also be calculated derivatives, such as the presence of certain edges and curves in an image, or lack thereof.
But there is no guarantee that will be the case, and you will often encounter data in textual or other unstructured forms. Luckily, there are a few techniques that when applied, clean up these scenarios.
Textual Categorical-Features
If you have a categorical feature, the way to represent it in your dataset depends on if it’s ordinal or nominal. For ordinal features, map the order as increasing integers in a single numeric feature.
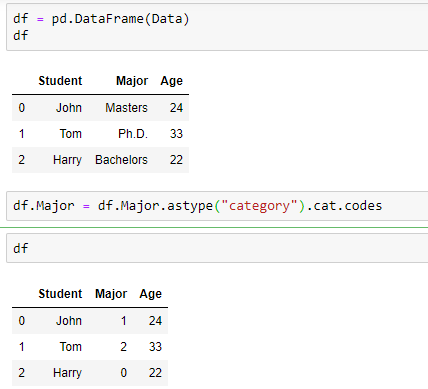
On the other hand, if your feature is nominal (and thus there is no obvious numeric ordering), then you have two options. The first is you can encoded it similar as you did above. This would be a fast-and-dirty approach. This may or may not cause problems for you in the future. If you aren’t getting the results you hoped for, or even if you are getting the results you desired but would like to further increase the result accuracy, then a more precise encoding approach would be to separate the distinct values out into individual boolean features:

These newly created features are called boolean features because the only values they can contain are either 0 for non-inclusion, or 1 for inclusion. Pandas .get_dummies() method allows you to completely replace a single, nominal feature with multiple boolean indicator features. This method is quite powerful and has many configurable options, including the ability to return a SparseDataFrame, and other prefixing options. It’s benefit is that no erroneous ordering is introduced into your dataset.
Pure Textual Features
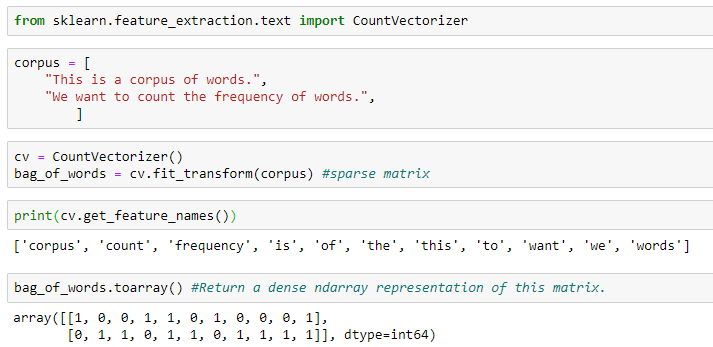
If you are trying to “featurize” a body of text such as a webpage, a tweet, a passage from a newspaper, an entire book, or a PDF document, creating a corpus of words and counting their frequency is an extremely powerful encoding tool. This is also known as the Bag of Words model, implemented with the CountVectorizer() method in SciKit-Learn.
Graphical Features
In addition to text and natural language processing, bag of words has successfully been applied to images by categorizing a collection of regions and describing only their appearance, ignoring any spatial structure. However this is not the typical approach used to represent images as features, and requires you come up with methods of categorizing image regions. More often used methods include:
- Split the image into a grid of smaller areas, and attempt feature extraction at each locality. Return a combined array of all discovered. features
- Use variable-length gradients and other transformations as the features, such as regions of high / low luminosity, histogram counts for horizontal and vertical black pixels, stroke and edge detection, etc.
- Resize the picture to a fixed size, convert it to grayscale, then encode every pixel as an element in a uni-dimensional feature array.
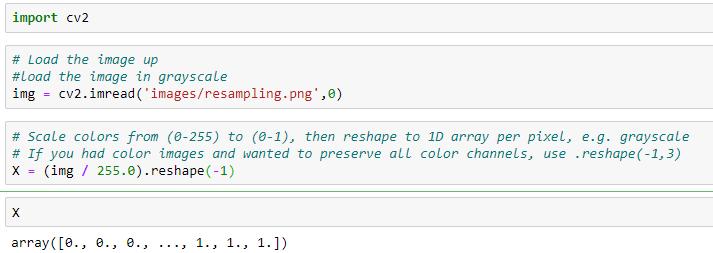
If you’re wondering what the :: is doing, that is called extended slicing. Notice the .reshape(-1) line. This tells Pandas to take your 2D image and flatten it into a 1D array. This is an all purpose method you can use to change the shape of your dataframes, so long as you maintain the number of elements. For example reshaping a [10, 10] to [100, 1] or [4, 25], etc. Another method called .ravel() will do the same thing as .reshape(-1), that is unravel a multi-dimensional NDArray into a one dimensional one. The reason why its important to reshape your 2D array images into one dimensional ones is because each image will represent a single sample, and Sklearn expects your dataframe to be shapes [num_samples, num_features].
Feature Selection
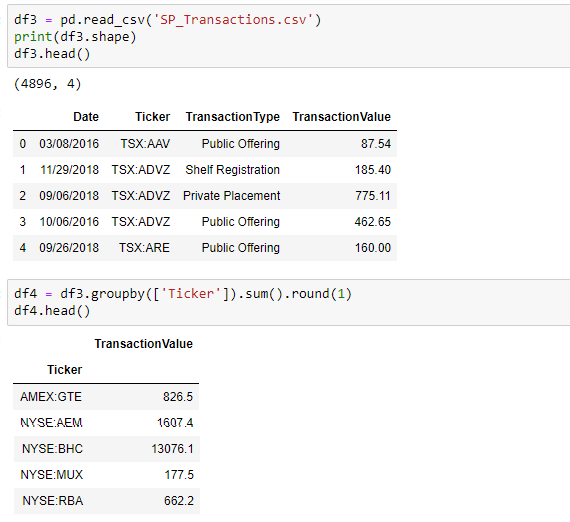
Most of the times, we will have many non-informative features. For Example, Name or ID variables and it results in “garbage-in, garbage-out”. Also, extra features make a model complex, time-consuming, and harder to implement in production. Many machine learning algorithms suffer from the curse of dimensionality — that is, they do not perform well when given a large number of variables or features. So it’s better to remove highly irrelevant or redundant features to simplify the situation and improve performance.
For instance, if your dataset have columns you don’t need, you can remove them using drop() method by specifying the name of columns. Axis=1 tells that deletion will happen column-wise while axis=0 will imply that deletion will happen row-wise.

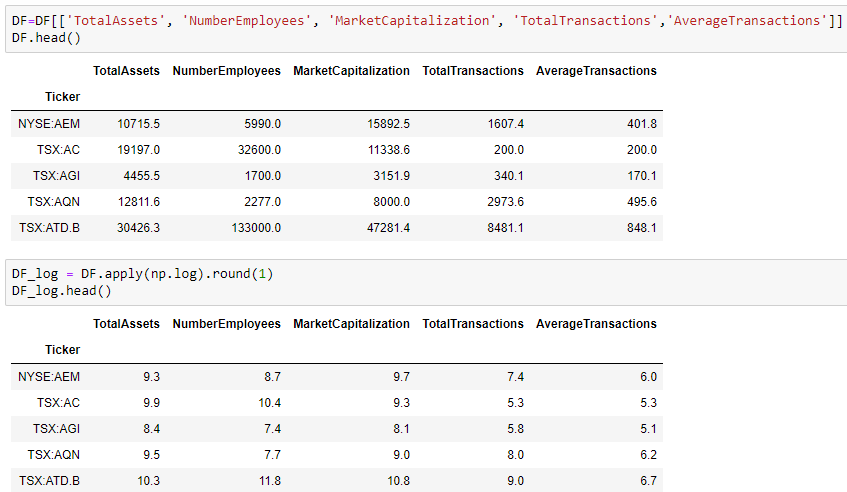
Or, if you want only select columns for analysis or visualization purposes, you can select those columns by enclosing them within double square brackets.
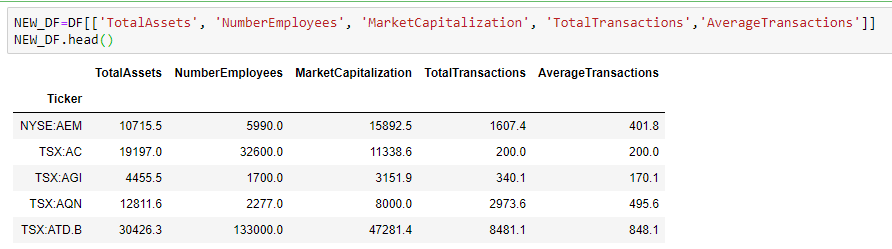
Sometimes, we want to remove a feature but use it as an index instead. We can do this by specifying the column name as index during data load method.

We can set the column as index later as well by using set_index() method.

We can further improve the situation of having too many features through dimensionality reduction.
Commonly used techniques are:
- PCA (Principal Component Analysis) — Considered a more statistical approach than machine learning approach. It tries to preserve the essential parts that have more variation of the data and remove the non-essential parts with fewer variation. One important thing to note that it is an unsupervised dimensionality reduction technique, where you can cluster the similar data points based on the correlation between them without any labels.
- t-SNE (t-Distributed Stochastic Neighboring Entities) — In this approach, target number of dimensions is typically 2 or 3 which means that t-SNE is used a lot for visualizing your data as visualizing data with more than 3 dimensions is not easy for human brain. t-SNE has remarkable capability of keeping close points from multi-dimensional space close in the two-dimensional space.
- Feature embedding — It is based on training a separate machine learning model to encode a large number of features into small number of features
Feature Transformation
Pandas will automatically attempt to figure out the best data type to use for each series in your dataset. Most of the time it does this flawlessly, but other times it fails horribly! Particularly the .read_html() method is notorious for defaulting all series data types to Python objects. You should check, and double-check the actual type of each column in your dataset to avoid unwanted surprises. If your data types don’t look the way you expected them, explicitly convert them to the desired type using the .to_datetime(), .to_numeric(), and .to_timedelta() methods:

Take note how to_numeric properly converts to decimal or integer depending on the data it finds. The errors=’coerce’ parameter instructs Pandas to enter a NaN at any field where the conversion fails.
Sometimes, even though the data type is correct, but we still need to modify the values in features. Example — we need to divide all the values by 10 or we need to convert them to their logarithmic values.
Feature Engineering
Just as oil needs to be refined before it is used, similarly data needs to be refined before we use it for machine learning. Sometimes, we need to derive new features out of existing features. The process of extracting new features from existing ones is called feature engineering. Classical Machine Learning depends on feature engineering much more than Deep Learning.
Below are some types of Feature Engineering.
- Aggregation — New features are created by getting a count, sum, average, mean, or median from a group of entities.
- Part-Of — New features are created by extracting a part of data-structure. E.g. Extracting the month from a date.
- Binning — Here you group your entities into bins and then you apply those aggregations over those bins. Example — group customers by age and then calculating average purchases within each group
- Flagging—Here you derive a boolean (0/1 or True/False) value for each entity
Example — we need to summarize data by finding its sum, average, minimum or maximum value and then creating new features with those new values.