

Introducing the exploretransform package for Python
Summary:
- Data scientists spend 60% of their time on cleaning and organizing data. Collecting data sets comes second at 19% of their time, meaning data scientists spend around 80% of their time on preparing and managing data for analysis¹
- 76% of data scientists view data preparation as the least enjoyable part of their work²
In this article, I will be demonstrating Python’s exploretransform package. It can save time during data exploration and transformation and hopefully make your data preparation more enjoyable!
Overview:
I originally developed exploretransform for use in my own projects, but I figured it might be useful for others. My intention was to create a simple set of functions and classes that returned results in common Python data formats. This would enable practitioners to easily utilize the outputs or extend the original functions as part of their workflows.
How to use exploretransform:
Installation and import
!pip install exploretransformimport exploretransform as et
Let’s start by loading the Boston corrected dataset.
df, X, y = et.loadboston()
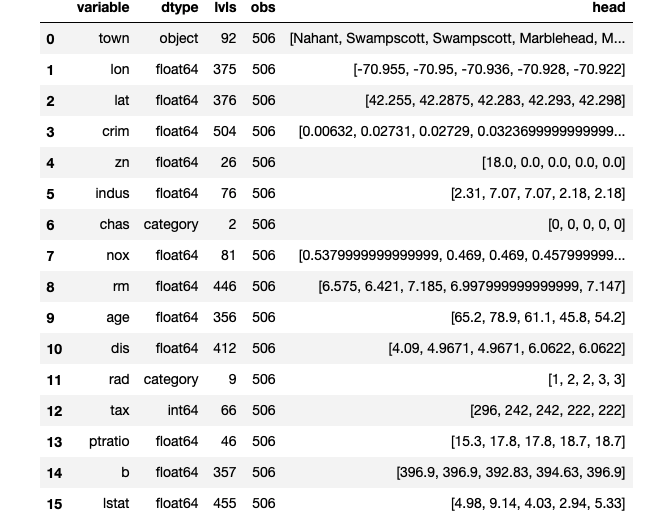
At this stage, I like to check that the data types align with the data dictionary and first five observations. Also, the # of lvls can indicate potential categorical features or features with high cardinality. Any dates or other data that need reformatting can also be detected here. We can use peek() here.
et.peek(X)
After analyzing the data types, we can use explore() to identify missing, zero, and infinity values.
et.explore(X)

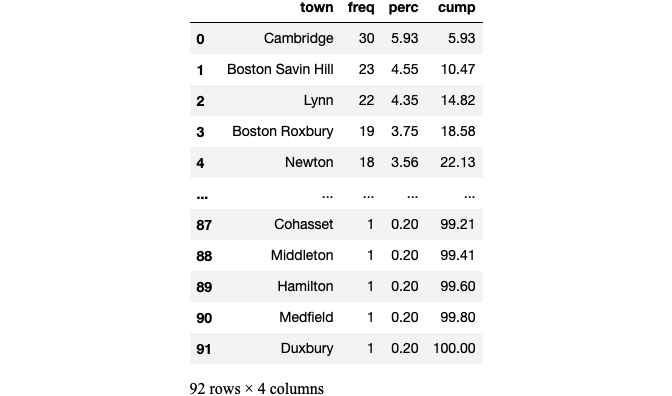
Earlier, we saw that town was likely a categorical feature with high cardinality. We can use freq() to analyze categorical or ordinal features providing the count, percent, and cumulative percent for each level
t = et.freq(X['town'])t
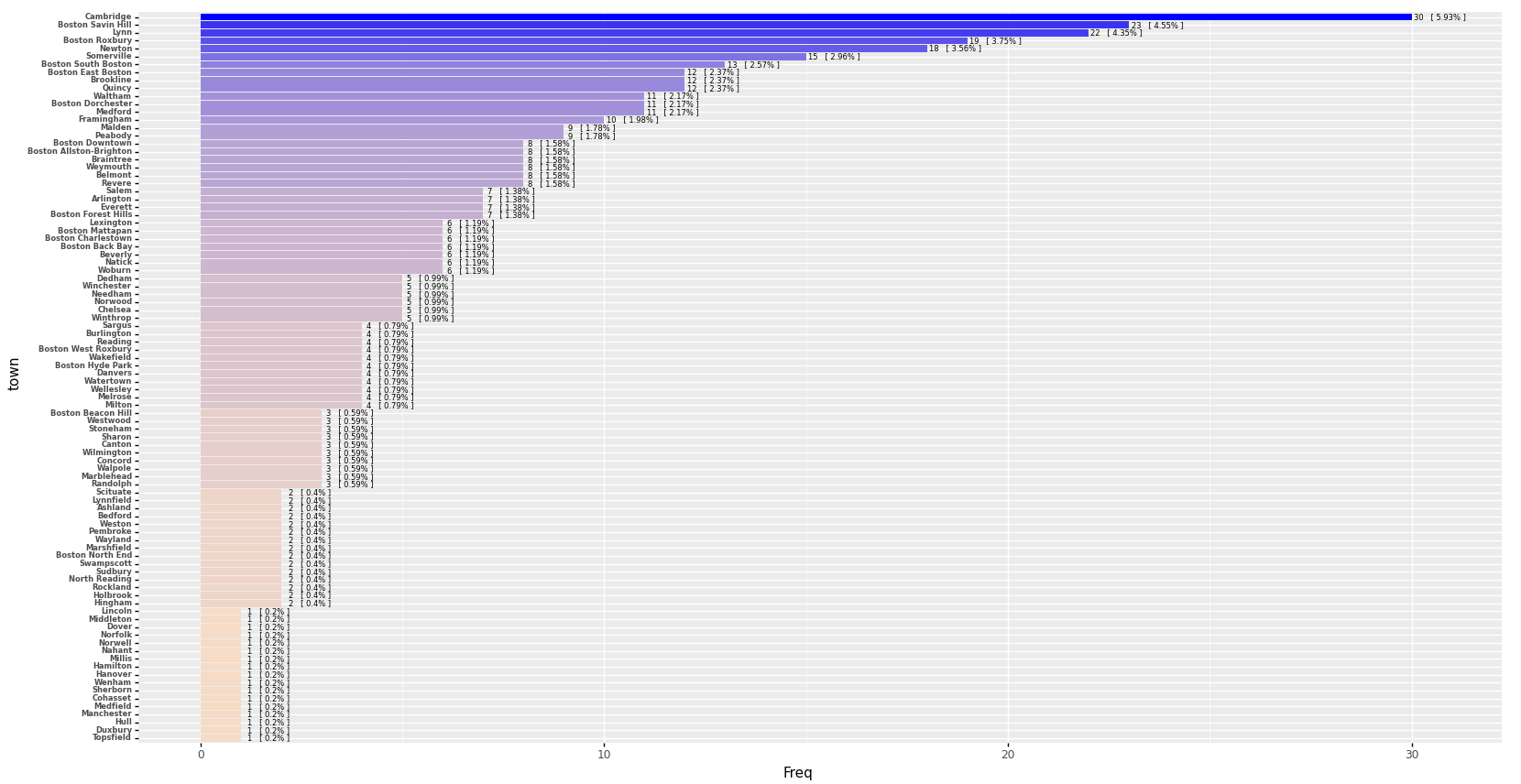
To visualize the resutls of freq() we can use plotfreq(). It generates a bar plot showing the levels in descending order.
et.plotfreq(t)
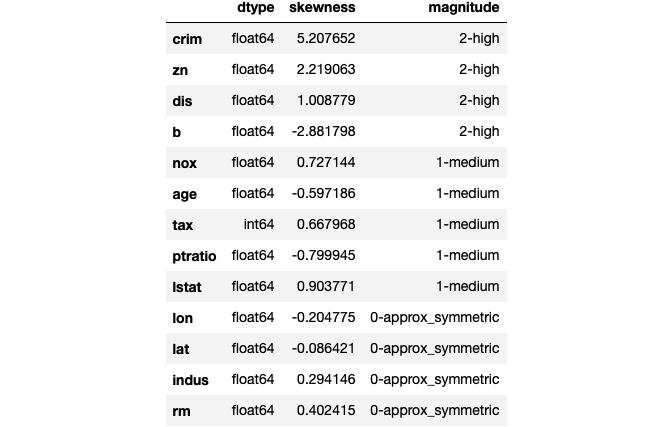
To pair with histograms you probably normally examine, skewstats() returns the skewness statistics and magnitude for each numeric feature. When you have too many features to easily plot, this function becomes more useful.
et.skewstats(N)
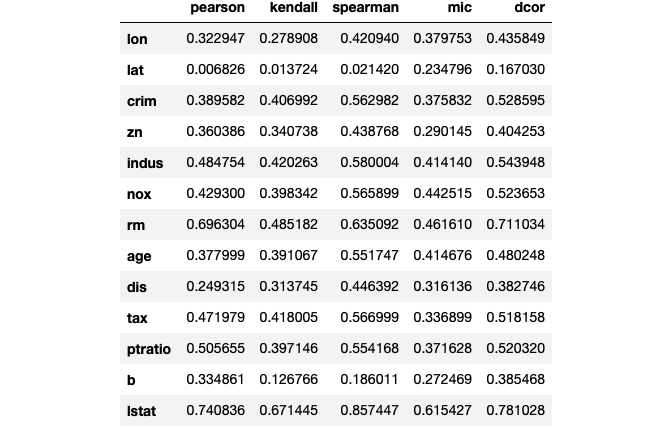
In order to determine the association between the predictors and target, ascores() calculates pearson, kendall, pearson, spearman, mic, and dcor statistics. A variety of these scores is useful since certain scores measure linear associations and others will detect non-linear relationships.
et.ascores(N,y)
Correlation matrices can get unwieldy once we hit a certain number of features. While the Boston dataset is well below this threshold, one can imagine that having a table might be more useful than a matrix when dealing with high dimensionality. Corrtable() returns a table of all pairwise correlations and uses the average correlation for the row and column in to decide on potential drop/filter candidates. You can use any of the methods you normally would with pandas corr function:
- pearson
- kendall
- spearman
- callable
N = X.select_dtypes('number').copy()c = et.corrtable(N, cut = 0.5, full= True, methodx = 'pearson')c


Based on the output of corrtable(), calcdrop() determines which features should be dropped.
et.calcdrop(c)['age', 'indus', 'nox', 'dis', 'lstat', 'tax']
ColumnSelect() is a custom transformer that selects columns for pipelines
categorical_columns = ['rad', 'town']cs = et.ColumnSelect(categorical_columns).fit_transform(X)cs

CategoricalOtherLevel() is a custom transformer that creates “other” level in categorical / ordinal data based on threshold. This is useful in situation where you have high cardinality predictors and when there is a possibility of having new categories appear in future data.
co = et.CategoricalOtherLevel(colname = 'town', threshold = 0.015).fit_transform(cs)co.iloc[0:15, :]

CorrelationFilter() is a custom transformer that filters numeric features based on pairwise correlation. It uses corrtable() and calcdrop() to perform the drop evaluations and calcuations. For more information on how it works please see: Are you dropping too many correlated features?
cf = et.CorrelationFilter(cut = 0.5).fit_transform(N)cf

Conclusion:
In this article, I have demonstrated how the exploretransform package can help you accelerate your exploratory data analysis.
