

Exploring the Unknown [Data]

This article is going to be about the first look every data enthusiast has taken into their project’s dataset. Before machine learning, before modeling, before feature selection — there has to be a fundamental understanding of the data you are using. That’s what we are doing — exploring. This article is about EDA, exploratory data analysis.
We will take it through several steps of analysis and even introduce a few techniques that help us determine the best course of action. For this article, I am going to assume you understand the difference between continuous and categorical data and knowledge about the different packages Python has to offer.
First, we are going to load a dataset that is relatively small and easy to understand. Luckily, Seaborn has a few datasets to choose from and I’ve decided to go with the ‘tips’ dataset and with it some other packages for this session like Matplotlib, Pandas, and SciPy. So the first step is to load it into a data frame in order to be used.https://medium.com/media/6c7e79e9b296e4dca7f88a5b12640557
Next, we look at a small portion of the data frame using the .head() method in order to understand the features that come along with the dataset.https://medium.com/media/6e7511a71b794ffb20564354ee9e1e61
And that gives us the output:
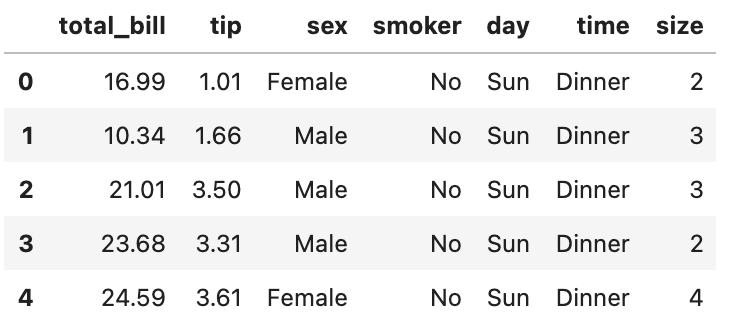
Now that we have looked at the dataset in order to make sure it loaded correctly and to get a feel of the features we can begin.
0. Looking at the Data Frame Shape
Before we look at the different features, I would suggest using .shape method. It returns a simple tuple that returns the dimensions of the data frame.https://medium.com/media/05ee5cda462a16d05a99436fa4ead569
The output for the tips data frame is:

While we are not going to necessarily need it for this data frame, you may run into data sets with hundreds of features and thousands of rows.
1. Descriptive Statistics
Python has a great method to use when you want an overview of a dataset. That is the .describe() method. Describe, when used on a data frame, allows us to see the statistical breakdown of the data frame. It is a great place to start and we can tailor it to the types of features we have. In this data frame, we have both continuous and categorical features. The statistical breakdown works differently on either one but you can use .describe() on both.https://medium.com/media/78142b25b9698dea407496876fa38d1a
The output for both at the same time is interesting, so let’s take a look.

The output from the code gives us insight into the statistics of the data frame. At the top of the breakdown is information about the data frame itself. The count is the number of observations (rows) that are in the data frame.
Before I go into the rest of the rows, I want to point out the NaN values. When you use the .describe() method on all of the features at once you apply all the statistics to all of them. This means that you will have statistics that aren’t applicable to one feature or another. For instance, the mean doesn’t make sense on a feature using days of the week. Mean is for numbers, the day of the week is a word. The same goes for unique — you can’t ask for the unique values of tips because there could be any number of different tip amounts.
Below that, are the statistics for categorical values. I am going to give a breakdown of the rest of the categorical statistics.
Remember, the list below will results in a NaN for continuous variables.
Categorical Statistics:
- Unique — how many different entries are in the variable.
- Top — the categorical answer that appears most frequently in the data frame
- Freq— the number of times the value that the most in a data frame
Next are the continuous variables and will result in a NaN for categorical variables.
Continuous Statistics:
- Mean — the average of all of the observations in that feature
- Std — the standard deviation of all of the variables in that feature
- Min — the lowest value out of all the observations
- 25% — this number is the location where the lowest quartile is
- 50% — this is the median of the feature
- 75% — this is where the upper quartile is
- Max — the largest value of the feature
I would recommend using the include=’all’ parameter when using the .describe() method. It saves time and is still very easy to understand.
2. Groupby
An expansion of the .describe() method use is using the .groupby() method.We can delve deeper into different features and use that information to make more informed decisions. Assume you want to know if there is any relationship between the different days a meal was eaten and the amount on the total bills.
An example of the .groupby() method below allows us to check the mean of the total bill and the size of the party based on the day the meal was taken.https://medium.com/media/f3195fd3e2aa18ea27eba0530f4e1966
When this code was run, it returned the following:
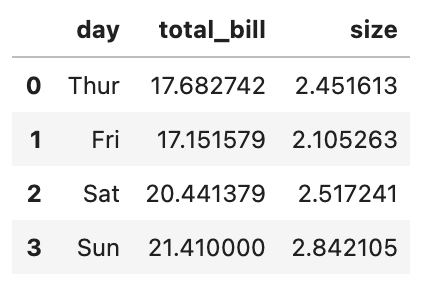
What is seen above is each day with the average value of the total bill and the size of the party. This can be done with any combination of continuous variables. More documentation on Pandas .groupby() can be found here.
A sidenote on the .groupby() method is the .value_counts() method. This returns the count for each unique entry. For instance, we apply it to the day categories in order to see how the days stack up against each other.https://medium.com/media/f0290504be63141f85c0b00369b46a49
The return is:

The default order is descending so the method returns the most frequently occurring day at the top. Notice the last line that has the information Name and type. This is simply referring to the name of the column that was counted and the type of information it returned in the picture above. Each of the counts returned is done so in the int64 format.
3. Correlation
Testing for correlation is the process of establishing a relationship or connection between two or more measures. Right now, we are going to look at whether an increase in the total bill results in an increase in the tip left for the server.
Our first test can be an easy graph where we look at a scatter plot of the independent variable total_bill vs the dependent variable tip.https://medium.com/media/9efc6fa1e5788d7c7c947a053b64bf58
And we get the plot:
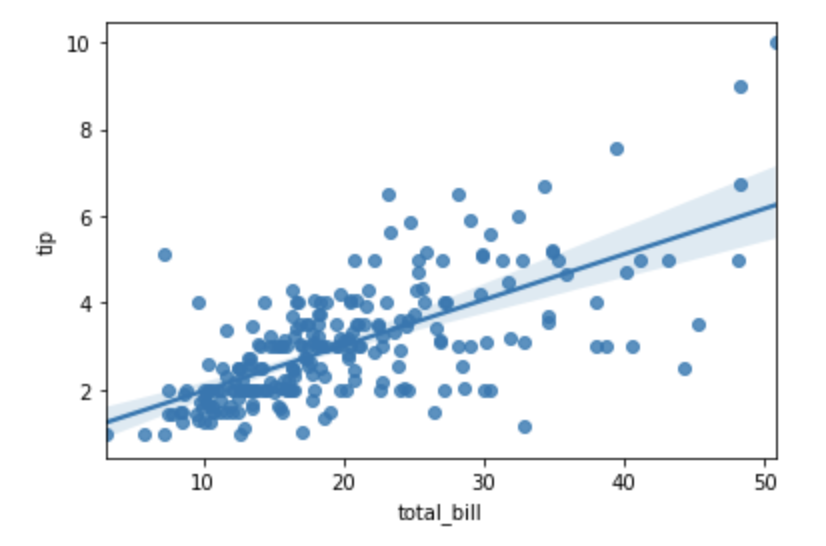
From the plot, we can see there is some linear relationship between the two variables. However, just because two variables seem to increase at the same time doesn’t mean that we know to what degree they both change. For this analysis, we need a more refined method of seeking correlation using statistics.
4. Correlation Statistics
To understand the idea of correlation statistics on a fundamental level, we need to know about two concepts. The Pearson Coefficient and the P-Value. First, let’s talk about the Pearson Coefficient.
Pearson Coefficient
The Pearson Coefficient a statistic that measures the linear correlation between two variables a and b. It has a value between +1 and −1. A value of +1 is a total positive linear correlation, 0 is no linear correlation, and −1 is a total negative linear correlation.
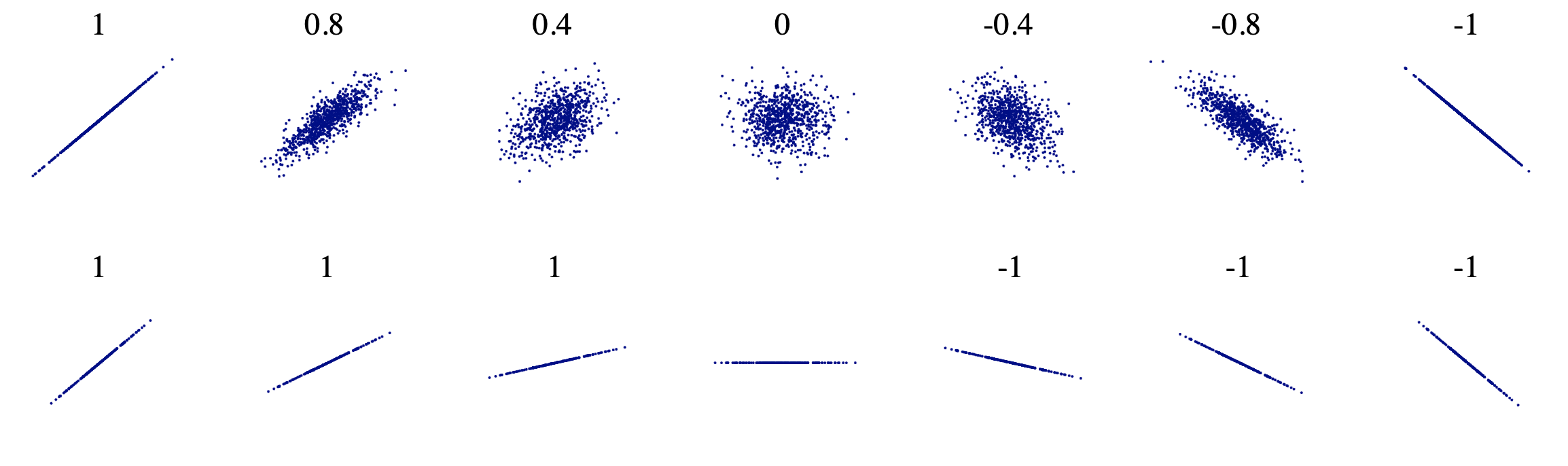
As stated above, the correlation of +1 and -1 are very strong correlations, positively, and negatively respectively. A strong correlation does not indicate the slope of the line but rather only the tightness of fit to the sloped line.
P-Value
The p-value is a measure of the probability that an observed difference could have occurred just by random chance. The lower the p-value, the less likely the connection between the two variables happened randomly.
SciPy Statsmodel Package
Finally, we will use Python to determine the Pearson Coefficient and the p-value of the total bill’s impact on the change in the tip given. Working off of the Statsmodel library of the SciPy package, we use the pearsonr() function.https://medium.com/media/df5e69f39ba9d832d18f0734b97940d7Using the Pearson Correlation function from SciPy
The output from the code above is:

Analyzing our output we can come to two very important conclusions. Firstly, the Pearson coefficient is relatively high. With a value of 0.67, there is a relatively strong positive correlation between the total bill and the tips given.
Secondly, the p-value is very small. So small, in fact, that we can reject the idea that the correlation between the two variables is insignificant.
Conclusion
To summarize what we’ve learned today:
- It is important to get a feel for the dimensions of a data frame before beginning to work with it.
- Usage of the .describe() method to examine the continuous and categorical variables
- We use .groupby() to see how specific attributes stack up in terms of aggregate functions
- Correlation is the idea that two variables change at the same time.
- Pearson Coefficient determines the correlation value. +1 is a strong positive correlation, -1 is a strong negative correlation. 0 is no correlation.
- The p-value dictates how likely something is to occur. A large p-value means that a thing occurring happened by chance. A very small p-value means that a thing occurred not by chance, but because it has a good chance of being statistically significant.
I hope this guide helped you with the beginnings of your data science project.

{kind=link}