

Investigating Population, Gender Equality in Education & Income for Singapore, United States and China
Exploratory Data Analysis (EDA) is one of the most important aspect in every data science or data analysis problem. It provides us greater understanding on our data and can possibly unravel hidden insights that aren’t that obvious to us. This post will focus more on graphical EDA in Python using matplotlib, regression line and even motion chart!
Dataset
The dataset we are using for this article can be obtained from Gapminder, and drilling down into Population, Gender Equality in Education and Income.
The Population data contains yearly data regarding the estimated resident population, grouped by countries around the world between 1800 and 2018.
The Gender Equality in Education data contains yearly data between 1970 and 2015 on the ratio between female to male in schools, among 25 to 34 years old which includes primary, secondary and tertiary education across different countries
The Income data contains yearly data of income per person adjusted for differences in purchasing power (in international dollars) across different countries around the world, for the period between 1800 and 2018.
EDA on Population
Let’s first plot the population data over time, and focus mainly on the three countries Singapore, United States and China. We will use matplotlib library to plot 3 different line charts on the same figure.
import pandas as pd
import matplotlib.pylab as plt
%matplotlib inline# read in data
population = pd.read_csv('./population.csv')# plot for the 3 countries
plt.plot(population.Year,population.Singapore,label="Singapore")
plt.plot(population.Year,population.China,label="China")
plt.plot(population.Year,population["United States"],label="United States")# add legends, labels and title
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('Population Growth over time')
plt.show()
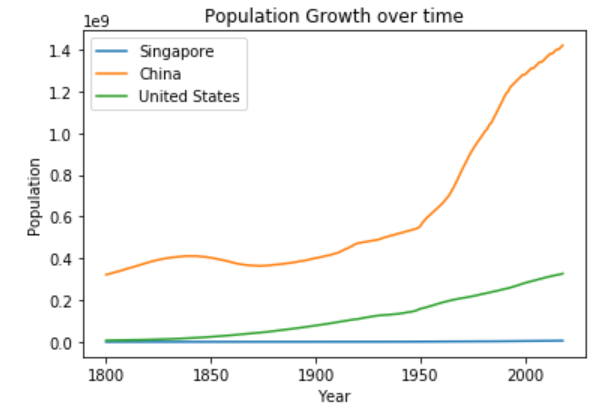
As seen in the figure, the population values for the 3 countries Singapore, China and United States are increasing over time, though Singapore is not that visible since the axis is in billions, while the population in Singapore is only in the millions.
Now, let’s try to fit a linear regression line using linregressto the Singapore population data and plot the linear fit. We can even try predicting the Singapore population in 2020 and 2100.
from scipy.stats import linregress
# set up regression line
slope, intercept, r_value, p_value, std_err = linregress(population.Year,population.Singapore)
line = [slope*xi + intercept for xi in population.Year]# plot the regression line and the linear fit
plt.plot(population.Year,line,'r-', linewidth=3,label='Linear Regression Line')
plt.scatter(population.Year, population.Singapore,label='Population of Singapore')
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('Population Growth of Singapore over time')
plt.show()# Calculate correlation coefficient to see how well is the linear fit
print("The correlation coefficient is " + str(r_value))
## Use the linear fit to predict the resident population in Singapore in 2020 and 2100.
# Using equation y=mx + c, i.e. population=slope*year + intercept
print("The predicted population in Singapore in 2020 will be " + str((slope*2020)+intercept))
print("The predicted population in Singapore in 2100 will be " + str((slope*2100)+intercept))
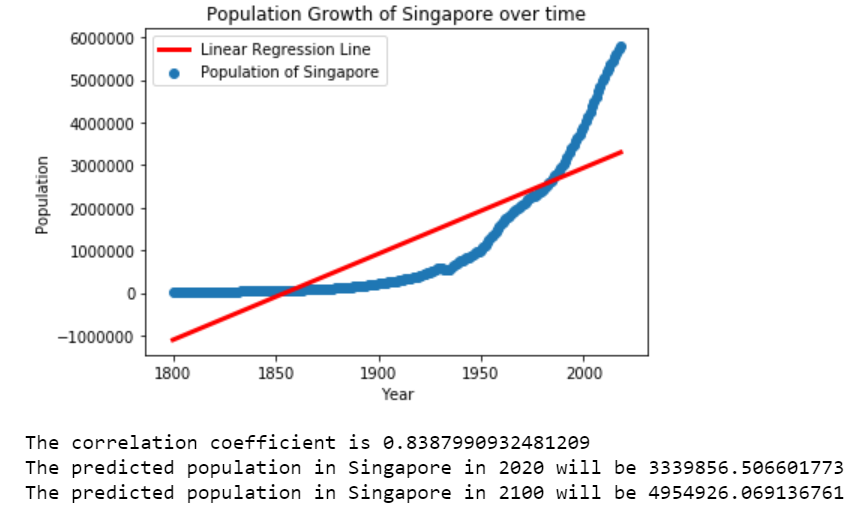
From the figure, we see that the linear fit did not seem to fit the Population of Singapore that well though we have a correlation coefficient close to 1. The prediction of the population was also well off as the current population of Singapore in 2020 is around 5.6 million, which is way above the 3.4 million predicted.
Notice that the population before 1850s were negative, which is definitely impossible. Since Singapore is founded in 1965, let’s filter to only use data from 1965 onwards.
from scipy.stats import linregress
# set up regression line
slope, intercept, r_value, p_value, std_err = linregress(population.Year[population.Year>=1965],population.Singapore[population.Year>=1965])
line = [slope*xi + intercept for xi in population.Year[population.Year>=1965]]plt.plot(population.Year[population.Year>=1965],line,'r-', linewidth=3,label='Linear Regression Line')
plt.scatter(population.Year[population.Year>=1965], population.Singapore[population.Year>=1965],label='Singapore')
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Population')
plt.title('Population Growth of Singapore from 1965 onwards')
plt.show()# Calculate correlation coefficient to see how well is the linear fit
print("The correlation coefficient is " + str(r_value))
## Use the linear fit to predict the resident population in Singapore in 2020 and 2100.
# Using equation y=mx + c, i.e. population=slope*year + intercept
print("The predicted population in Singapore in 2020 will be " + str((slope*2020)+intercept))
print("The predicted population in Singapore in 2100 will be " + str((slope*2100)+intercept))

This linear regression line fits so much better as shown in the graph as well as the correlation coefficient. Furthermore, the predicted 2020 population is exactly what it is in Singapore currently, and let’s hope the 2100 population is not true since we know the land area in Singapore is considerably small.
EDA on Gender Equality in Education
Moving onto the second dataset, let’s try to plot the gender ratio (females to males) in schools for Singapore, China and the United States over time. We can also look at the maximum and minimum gender ratio percentage in Singapore.
# reading in data
gender_equality = pd.read_csv('./GenderEquality.csv')
# plot the graphs
plt.plot(gender_equality.Year,gender_equality.Singapore,label="Singapore")
plt.plot(gender_equality.Year,gender_equality.China,label="China")
plt.plot(gender_equality.Year,gender_equality["United States"],label="United States")# set up legends, labels and title
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Gender Ratio of Female to Male in school')
plt.title('Gender Ratio of Female to Male in school over time')
plt.show()# What are the maximum and minimum values for gender ratio in Singapore over the time period?
print("The maximum value is: " + str(max(gender_equality.Singapore)) + " and the minimum is "
+ str(min(gender_equality.Singapore)))

The gender ratios were generally increasing over time as seen in the output above. Gender Ratio for China and Singapore were increasing linearly over time. For United States, there was certain periods in which the gender ratio were stagnant before increasing again. The minimum gender ratio for Singapore was 79.5 while the maximum was 98.9, and this was expected since education in Singapore in the past was considerably more important for males than females.
Let’s plot the linear regression line on the gender ratio for Singapore.
# plot the regression line
slope, intercept, r_value, p_value, std_err = linregress(gender_equality.Year,gender_equality["Singapore"])
line = [slope*xi + intercept for xi in gender_equality.Year]plt.plot(gender_equality.Year,line,'r-', linewidth=3,label='Linear Regression Line')
plt.plot(gender_equality.Year, gender_equality["Singapore"],label='Singapore')
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Gender Ratio of Female to Male in school')
plt.title('Gender Ratio of Female to Male in school for Singapore over time')
plt.show()
print("The correlation coefficient is " + str(r_value))

The correlation coefficient suggested that it is a good fit and gender ratio will potentially reach 100% in the future. This could be possible as education is no longer a privilege in Singapore as both males and females have equal opportunities in receiving formal education.
EDA on Income
Let’s finally move to Income data and plot the income of Singapore, United States and China over time.
# read in data
income = pd.read_csv('./Income.csv')
# plot the graphs
plt.plot(income.Year,income.Australia,label="Singapore")
plt.plot(income.Year,income.China,label="China")
plt.plot(income.Year,income["United States"],label="United States")
# set up legends, labels, title
plt.legend(loc='best')
plt.xlabel('Year')
plt.ylabel('Income per person')
plt.title('Income per person over time')
plt.show()

Surprisingly, the income per person in Singapore is comparable to the United States, with both above those in China.
Motion Chart — Visualising relationships over time
Now, let’s try to build a motion chart to visualise relationships over time for all three factors of Population, Gender Ratio and Income. In order to build a motion chart in Python, we will need motionchart library.
Before that, we will need to merge all three datasets into a single one to plot our motion chart easily. Merging can be done using common pandas commands.
# Convert columns into rows for each data set based on country and population/gender ratio/income
population=pd.melt(population,id_vars=['Year'],var_name='Country',value_name='Population')
gender_equality=pd.melt(gender_equality,id_vars=['Year'],var_name='Country',value_name='Gender Ratio')# Merge the 3 datasets into one on common year and country
income=pd.melt(income,id_vars=['Year'],var_name='Country',value_name='Income')
overall=pd.merge(population,gender_equality,how="inner",on=["Year","Country"])
overall=pd.merge(overall,income,how="inner",on=["Year","Country"])
To visualise relationship over time, we will need to set the Year attribute as the key in our motion chart. Our x-axis will be the Gender Ratio, y-axis the Income, size of the bubble for Population and lastly, colour of bubble for the Country.
from motionchart.motionchart import MotionChart# setting up the style
%%html
<style>
.output_wrapper, .output {
height:auto !important;
max-height:1000px;
}
.output_scroll {
box-shadow:none !important;
webkit-box-shadow:none !important;
}
</style># plotting the motion chart
mChart = MotionChart(df = overall)
mChart = MotionChart(df = overall, key='Year', x='Gender Ratio', y='Income', xscale='linear'
, yscale='linear',size='Population', color='Country', category='Country')
mChart.to_notebook()
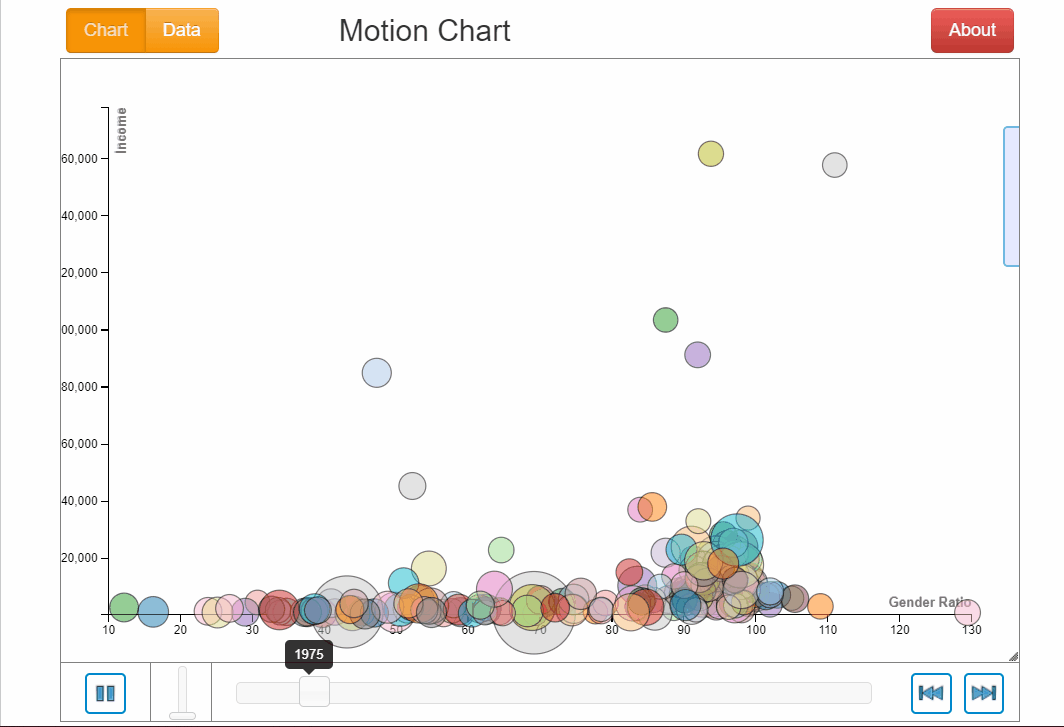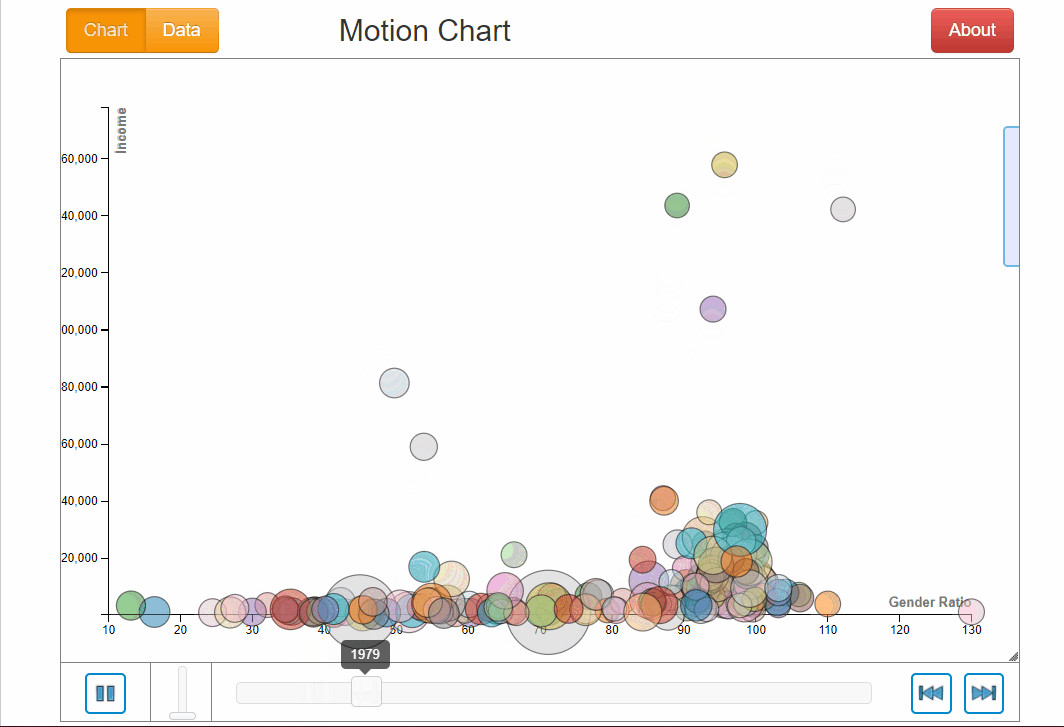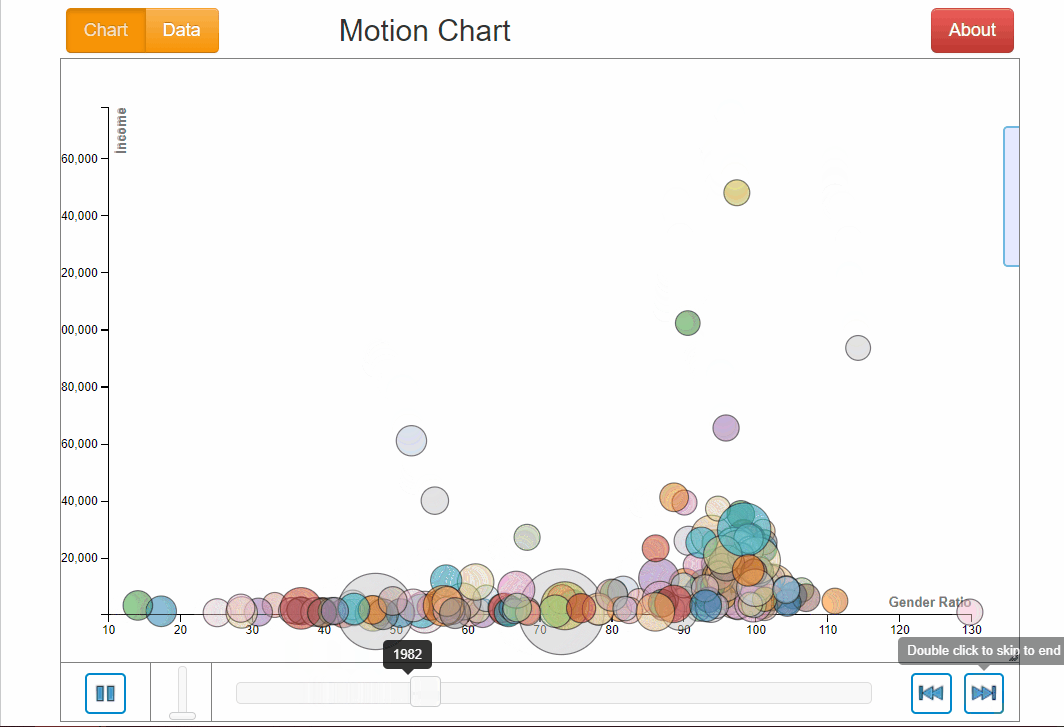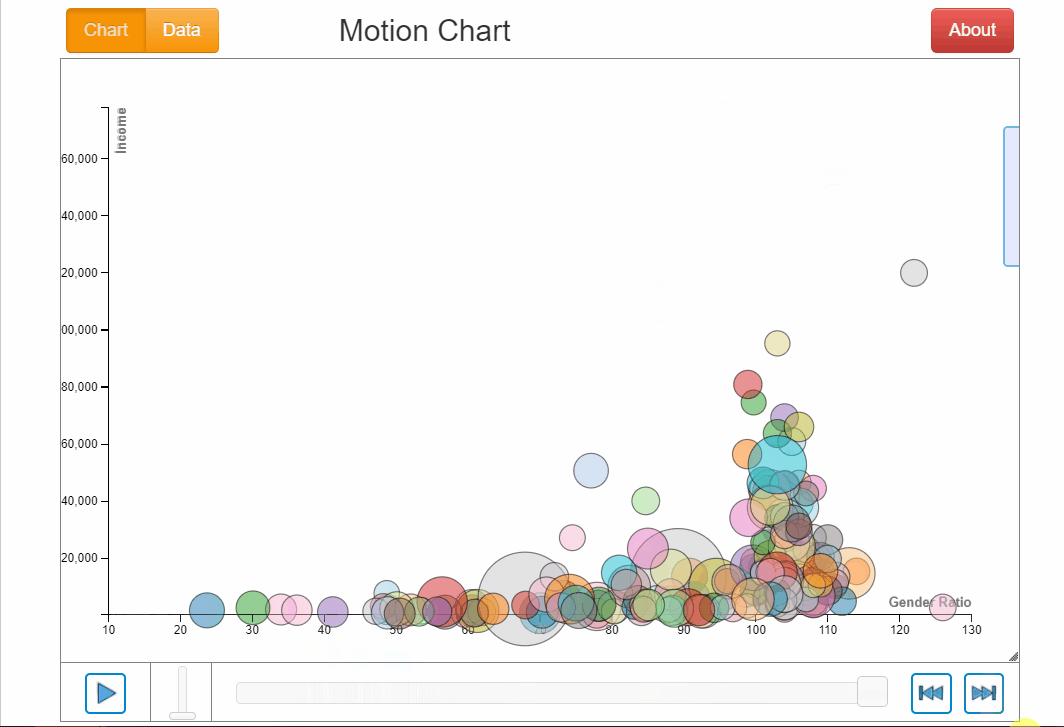
If we explore this motion chart, we know Afghanistan and Yemen had the lowest gender ratio in education of 23.7 and 30.1 respectively. Lesotho in South Africa has the highest gender ration throughout (note the little pink dot at the bottom right).
There is generally not a clear relationship between income and gender ratio in education. During the whole period of time, as gender ratio is generally increasing for all countries, income did not follow likewise by increasing nor did it decrease. There was a mix of being stagnant, increasing and decreasing which did not exhibit any clear relationship with gender ratio.
Let’s focus on building a motion chart for just Singapore.
mChart = MotionChart(df = overall.loc[overall.Country.isin(['Singapore'])])
mChart = MotionChart(df = overall.loc[overall.Country.isin(['Singapore'])], key='Year', x='Gender Ratio',
y='Income', xscale='linear', yscale='linear',size='Population', color='Country', category='Country')
mChart.to_notebook()

Interestingly for Singapore, other than the Population increasing over time, Gender Ratio in Education as well as Income seems to increasing constantly over time as well. Income was at 11400 in 1970 and it increased tremendously to 80900 in 2015.
Summary
In this article, we made use of Python matplotlib, linear regression as well as the fanciful motion charts to conduct exploratory data analysis on three datasets, mainly Population, Gender Ratio in Education & Income. Through these graphical methods, we can discover some insights on our data and potentially, allow us to make better predictions. Hope you guys enjoy this graphical approach to Exploratory Data Analysis in Python, and have fun playing with your fanciful motion charts!
