

An easy descriptive statistics approach to summarize the numeric and categoric data variables through the Measures of Central Tendency and Measures of Spread for every Exploratory Data Analysis process.
About the Exploratory Data Analysis (EDA)
EDA is the first step in the data analysis process. It allows us to understand the data we are dealing with by describing and summarizing the dataset’s main characteristics, often through visual methods like bar and pie charts, histograms, boxplots, scatterplots, heatmaps, and many more.
Why is EDA important?
- Maximize insight into a dataset (be able to listen to your data)
- Uncover underlying structure/patterns
- Detect outliers and anomalies
- Extract and select important variables
- Increase computational effenciency
- Test underlying assumptions (e.g. business intuiton)
Moreover, to be capable of exploring and explain the dataset’s features with all its attributes getting insights and efficient numeric summaries of the data, we need help from Descriptive Statistics.
Statistics is divided into two major areas:
- Descriptive statistics: describe and summarize data;
- Inferential statistics: methods for using sample data to make general conclusions (inferences) about populations.
This tutorial focuses on descriptive statistics of both numerical and categorical variables and is divided into two parts:
- Measures of central tendency;
- Measures of spread.
Descriptive statistics
Also named Univariate Analysis (one feature analysis at a time), descriptive statistics, in short, help describe and understand the features of a specific dataset, by giving short numeric summaries about the sample and measures of the data.
Descriptive statistics are mere exploration as they do not allows us to make conclusions beyond the data we have analysed or reach conclusions regarding any hypotheses we might have made.
Numerical and categorical variables, as we will see shortly, have different descriptive statistics approaches.
Let’s review the type of variables:

- Numerical continuous: The values are not countable and have an infinite number of possibilities (Someone’s age: 25 years, 4 days, 11 hours, 24 minutes, 5 seconds and so on to the infinite).
- Numerical discrete: The values are countable and have an finite number of possibilities (It is impossible to count 27.52 countries in the EU).
- Categorical ordinal: There is an order implied in the levels (January comes always before February and after December).
- Categorical nominal: There is no order implied in the levels (Female/male, or the wind direction: north, south, east, west).
Numerical variables

- Measures of central tendency: Mean, median
- Measures of spread: Standard deviation, variance, percentiles, maximum, minimum, skewness, kurtosis
- Others: Size, unique, number of uniques
One approach to display the data is through a boxplot. It gives you the 5-basic-stats, such as the minimum, the 1st quartile (25th percentile), the median, the 3rd quartile (75th percentile), and the maximum.

Categorical variables

- Measures of central tendency: Mode (most common)
- Measures of spread: Number of uniques
- Others: Size, % Highest unique
Understanding:
Measures of central tendency
- Mean (average): The total sum of values divided by the total observations. The mean is highly sensitive to the outliers.
- Median (center value): The total count of an ordered sequence of numbers divided by 2. The median is not affected by the outliers.
- Mode (most common): The values most frequently observed. There can be more than one modal value in the same variable.
Measures of spread
- Variance (variability from the mean): The square of the standard deviation. It is also affected by outliers.
- Standard deviation (concentrated around the mean): The standard amount of deviation (distance) from the mean. The std is affected by the outliers. It is the square root of the variance.
- Percentiles: The value below which a percentage of data falls. The 0th percentile is the minimum value, the 100th is the maximum, the 50th is the median.
- Minimum: The smallest or lowest value.
- Maximum: The greatest or highest value.
- The number of uniques (total distinct): The total amount of distinct observations.
- Uniques (distinct): The distinct values or groups of values observed.
- Skewness (symmetric): How much a distribution derives from the normal distribution.
>> Explained Skew concept in the next section. - Kurtosis (volume of outliers): How long are the tails and how sharp is the peak of the distribution.
>> Explained Kurtosis concept in the next section.
Others
- Count (size): The total sum of observations. Counting is also necessary for calculating the mean, median, and mode.
- % highest unique (relativity): The proportion of the highest unique observation regarding all the unique values or group of values.
Skewness
In a perfect world, the data’s distribution assumes the form of a bell curve (Gaussian or normally distributed), but in the real world, data distributions usually are not symmetric (= skewed).
Therefore, the skewness indicates how much our distribution derives from the normal distribution (with the skewness value of zero or very close).
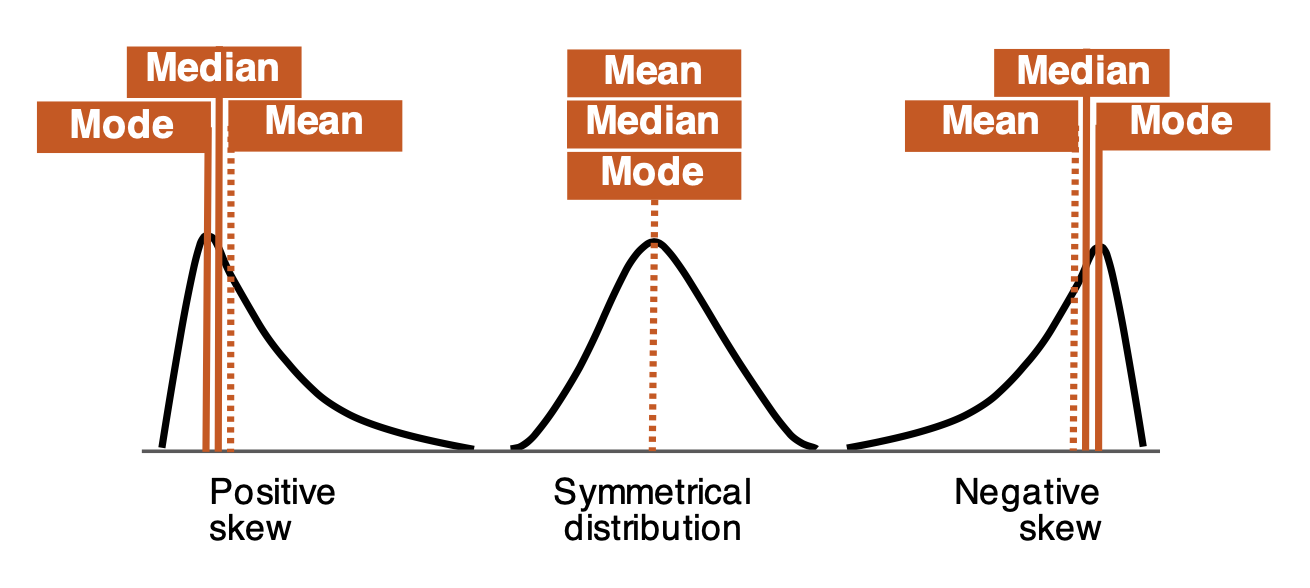
There are three generic types of distributions:
- Symmetrical [median = mean]: In a normal distribution, the mean (average) divides the data symmetrically at the median value or close.
- Positive skew [median < mean]: The distribution is asymmetrical, the tail is skewed/longer towards the right-hand side of the curve. In this type, the majority of the observations are concentrated on the left tail, and the value of skewness is positive.
- Negative skew [median > mean]: The distribution is asymmetrical and the tail is skewed/longer towards the left-hand side of the curve. In this type of distribution, the majority of the observations are concentrated on the right tail, and the value of skewness is negative.
Rule of thumbs:
- Symmetric distribution: values between –0.5 to 0.5.
- Moderate skew: values between –1 and -0.5 and 0.5 and 1.
- High skew: values <-1 or >1.
Kurtosis
kurtosis is another useful tool when it comes to quantify the shape of a distribution. It measures both how long are the tails, but most important, and how sharp is the peak of the distributions.
If the distribution has a sharper and taller peak and shorter tails, then it has a higher kurtosis while a low kurtosis can be observed when the peak of the distribution is flatter with thinner tails. There are three types of kurtosis:

- Leptokurtic: The distribution is tall and thin. The value of a leptokurtic must be > 3.
- Mesokurtic: This distribution looks the same or very similar to a normal distribution. The value of a “normal” mesokurtic is = 3.
- Platykurtic: The distributions have a flatter and wider peak and thinner tails, meaning that the data is moderately spread out. The value of a platykurtic must be < 3.
The kurtosis values determine the volume of the outliers only.
Kurtosis is calculated by raising the average of the standardized data to the fourth power. If we raise any standardized number (less than 1) to the 4th power, the result would be a very small number, somewhere close to zero. Such a small value would not contribute much to the kurtosis. The conclusion is that the values that would make a difference to the kurtosis would be the ones far away from the region of the peak, put it in other words, the outliers.
The Jupyter notebook — IPython
In this section, we will be giving short numeric stats summaries concerning the different measures of central tendency and dispersion of the dataset.
let’s work on some practical examples through a descriptive statistics environment in Pandas.
Start by importing the required libraries:
import pandas as pd
import numpy as np
import scipy
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
Load the dataset:df = pd.read_csv("sample.csv", sep=";")
Print the data:df.head()
Before any stats calculus, let’s just take a quick look at the data:df.info
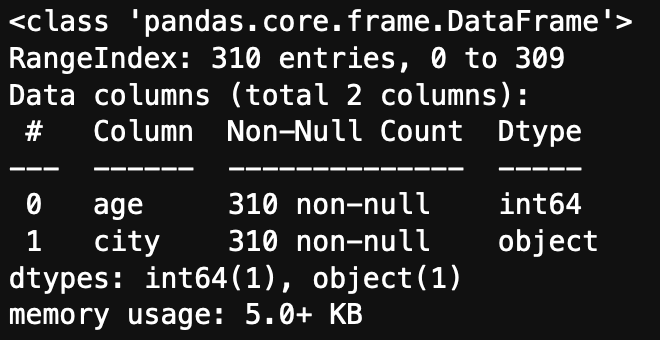
The dataset consists of 310 observations and 2 columns. One of the attributes is numerical, and the other categorical. Both columns have no missing values.
Numerical variable
The numerical variable we are going to analyze is age. First step is to visually observe the variable. So let’s plot an histogram and a boxplot.
plt.hist(df.age, bins=20)
plt.xlabel(“Age”)
plt.ylabel(“Absolute Frequency”)
plt.show()
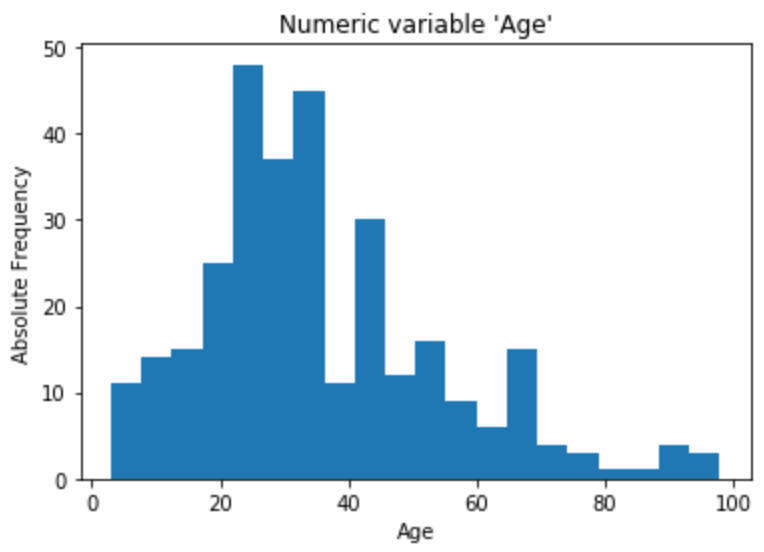
sns.boxplot(x=age, data=df, orient="h").set(xlabel="Age", title="Numeric variable 'Age'");

It is also possible to visually observe the variable with both a histogram and a boxplot combined. I find it a useful graphical combination and use it a lot in my reports.
age = df.agef, (ax_box, ax_hist) = plt.subplots(2, sharex=True, gridspec_kw= {"height_ratios": (0.8, 1.2)})mean=np.array(age).mean()
median=np.median(age)sns.boxplot(age, ax=ax_box)
ax_box.axvline(mean, color='r', linestyle='--')
ax_box.axvline(median, color='g', linestyle='-')sns.distplot(age, ax=ax_hist)
ax_hist.axvline(mean, color='r', linestyle='--')
ax_hist.axvline(median, color='g', linestyle='-')plt.legend({'Mean':mean,'Median':median})
plt.title("'Age' histogram + boxplot")ax_box.set(xlabel='')
plt.show()
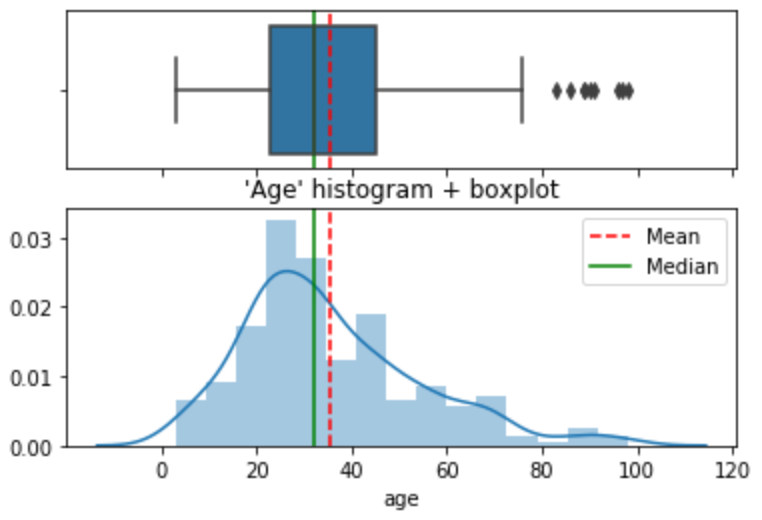
Measures of central tendency
1. Mean:df.age.mean()
35.564516129032256
2. Median:df.age.median()
32.0
Measures of spread
3. Standard deviation:df.age.std()
18.824363618000913
4. Variance:df.age.var()
354.3566656227164
5. a) Percentiles 25%:df.age.quantile(0.25)
23.0
b) Percentile 75%:df.age.quantile(0.75)
45.0
c) In one go:
df.age.quantile(q=[.25, .75)
0.25 23.0
0.75 45.0
Name: age, dtype: float64
6. Minimum and maximum:df.age.min(), df.age.max()
(3, 98)
7. Skewness (with scipy):scipy.stats.skew(df.age)
0.9085582496839909
8. Kurtosis (with scipy):scipy.stats.kurtosis(df.age)
0.7254158742250474
Others
9. Size (number of rows):df.age.count()
310
10. Number of uniques (total distinct)df.age.nunique()
74
11. Uniques (distinct):df.age.unique()
array([46, 22, 54, 33, 69, 35, 11, 97, 50, 34, 67, 43, 21, 12, 23, 45, 89, 76, 5, 55, 65, 24, 27, 57, 38, 28, 36, 60, 56, 53, 26, 25, 42, 83, 16, 51, 90, 10, 70, 44, 20, 31, 47, 30, 91, 7, 6, 41, 66, 61, 96, 32, 58, 17, 52, 29, 75, 86, 98, 48, 40, 13, 4, 68, 62, 9, 18, 39, 15, 19, 8, 71, 3, 37])
Categorical variable
The categorical variable we are going to analyze is city. Let’s plot a bar chart and get a visual observation of the variable.
df.city.value_counts().plot.bar()
plt.xlabel("City")
plt.ylabel("Absolute Frequency")
plt.title("Categoric variable 'City'")
plt.show()
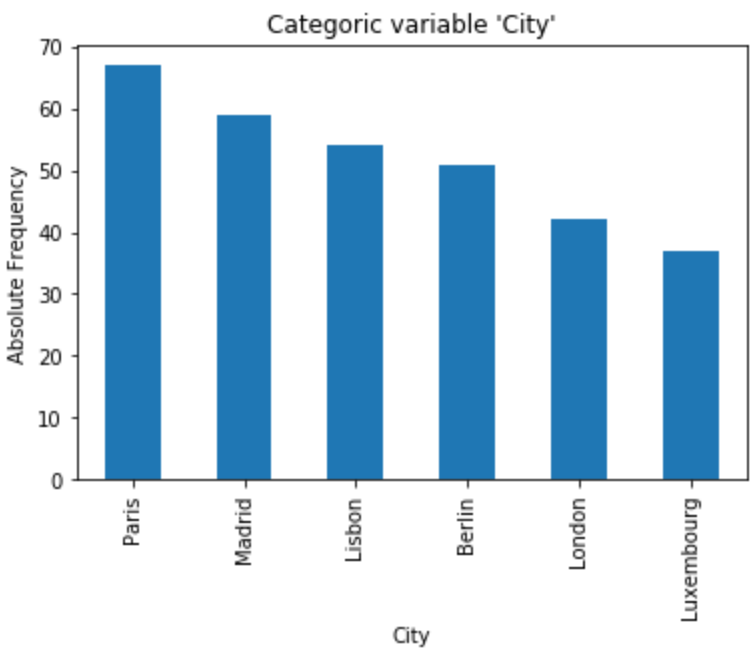
Measures of central tendency
1. Mode:df.city.mode()[0]
'Paris'
Measures of spread
2. Number of uniques:df.city.nunique()
6
3. Uniques (distinct):df.city.unique()
array(['Lisbon', 'Paris', 'Madrid', 'London', 'Luxembourg', 'Berlin'], dtype=object)
4. Most frequent unique (value count):df.city.value_counts().head(1)
Paris 67
Name: city, dtype: int64
Others
5. Size (number of rows):df.city.count()
310
6. % of the highest unique (fraction of the most common unique in regards to all the others):p = df.city.value_counts(normalize=True)[0]print(f"{p:.1%}")
21.6%
The describe() method shows the descriptive statistics gathered in one table. By default, stats for numeric data. The result is represented as a pandas dataframe.df.describe()

Adding other non-standard values, for instance, the ‘variance’.describe_var = data.describe()
describe_var.append(pd.Series(data.var(), name='variance'))

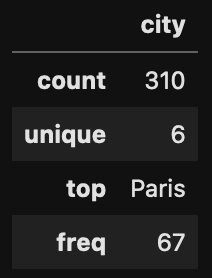
Displaying categorical data.df.describe(include=["O"])<=> df.describe(exclude=['float64','int64'])<=> df.describe(include=[np.object])
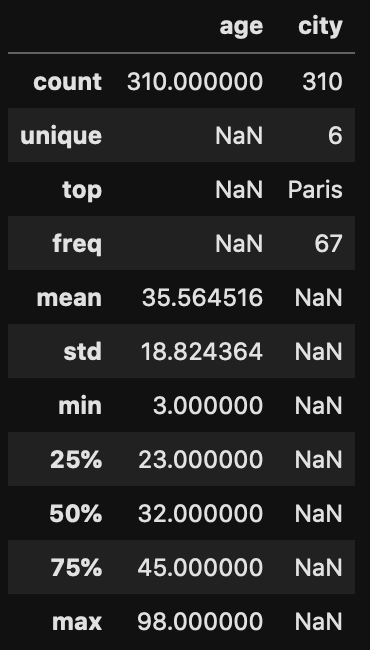
By passing the parameter include='all', displays both numeric and categoric variables at once.df.describe(include='all')
Conclusion
These are the basics of descriptive statistics when developing an exploratory data analysis project with the help of Pandas, Numpy, Scipy, Matplolib and/or Seaborn. When well performed, these stats help us to understand and transform the data for further processing.
