

Hadoop Distributed File System
In this post we will discuss about Hadoop Distributed File System.
Hadoop is divided into two parts :
1) HDFS – Storing files
2) MapReduce – Processing of file.
HDFS: It is a special file system for storing large data on a cluster of commodity hardware in a streaming access pattern. Streaming access pattern means you can write once, read any number of times but can’t change the content of that file once it is kept in HDFS.
HDFS is suitable for batch processing – data access has high throughtput rather than low latency. It supports very large data sets. It manage file storage across multiple disks. Each disk is available on different machine in a cluster.
Difference – Unix file system and HDFS
In Unix file system default size of the block is of 4KB. Suppose your file is of 6KB, then you require 2 blocks in Unix each of 4KB. So total 8KB is used, but actually you require 6KB that extra 2KB is wasted. In HDFS default size of the block is of 64MB (128MB). Suppose your file is of 200MB, then HDFS requires 4 blocks (3 of 64MB + 1 of 8MB). Extra space of 56MB in last block is not engaged. Insted extra space is relieved.
Why block size is of 64MB(128MB) ?
NameNode maintaining metadata for each block in HDFS. If block size is kept small,maintenance of metadata itself would engage much more space relatively. To reduce this overhead block size is kept large enough. Large enough block size reduces network traffic. Due to large block size Hadoop can fetch at a time 64MB of data for processing.
Services in Hadoop
1. Namenode
2. Datanode
3. NodeMananger
4. ResourceMananger
5. SecondaryNamenode
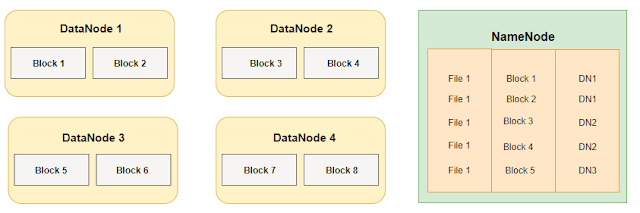
Namenode contains metadata of the datanodes. It is basically like table of contents(Index table). It maintains directory structure. Any request from client is passed through namenode.Datanode contains actual unstructured data.
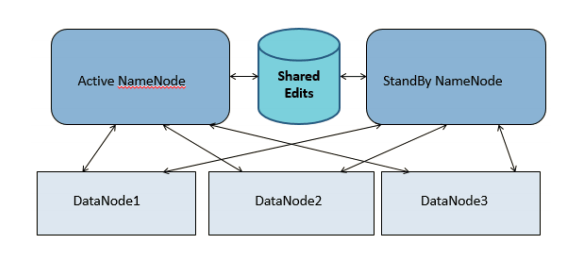
There are multiple number of Namenodes are present in production. Each stores metadata and block mapping of files and maintain directory structure. List of sub directories managed by namenode is called namespace volume. Blocks for files belonging to namespace is called block pool. So in case if one namenode is failed namespace volume managed by other namenode is still accessible. So entrie cluster dosent goes down.
S
Storing files in HDFS:

- Increase block size – Reduce parallelism
- Small block size – Increase overhead to maintain metadata
Time take to read a block data from disk is broken into 2 parts
Use metadata in the name node to lookup block locations
Read block from respective location
Detail working of HDFS:

1. The client has a file of size, say, 200MB and want to put in HDFS.
2. Client sends a request to a NameNode about list of available blocks.
3. NameNode, in response, provides the list of available blocks and maintains metadata of file (e.g. Block Number 1,3,5,7).
4. The client sends the file to available block and HDFS internally splits that file according to the block size.
5. This 200MB file is divided into a.txt(64MB), b.txt(64MB), c.txt(64MB) and d.txt(8MB). Default replication factor in hdfs is 3. Client puts the file a.txt in DataNode 1 (block 1) and this block is replicated into block numbered 2 and 4.
6. Block 4 sends an acknowledgement(ack) to block 2 and block 2 sends ack to block 1.
7. Block 1 gives ack to client. This ack contains information about replication of block 1 data.
8. After a specific interval of time every block sends block report and a heartbeat (default time is 3 second) to NameNode.
9. The block report contains the metadata of the block and the heartbeat of a node symbolizes that node is alive.
10. If any DataNode in the cluster fails, NameNode allocates another node which contains that replicated information and manages another free node to maintain the replication factor.
11. Succedingly, JobTracker comes into the picture.
12. JobTracker needs data for processing. So it contacts NameNode for block info. JobTracker sends code on particular DataNode for processing.
13. As in master slave communication JobTracker cannot directly contact DataNode, it contacts TaskTracker.
14. Map: The process where JobTracker sends information to TaskTracker.
15. TaskTracker then communicate with DataNode and processes the data available in DataNode.
16. Reducer resides in any of the DataNode that combines all o/p files.
17. Alongwith heartbeat, info about o/p file is stored in metadata.
18. The client will know o/p info by reading metadata and will directly fetch that o/p file.
19. If DataNode fails, then JobTracker assign the task to another DataNode where the replicated data is available.
How JobTracker tracks the alive status of TaskTracker? TaskTracker gives hearbeat to JobTracker after every 3 second.
