

YARN in hadoop
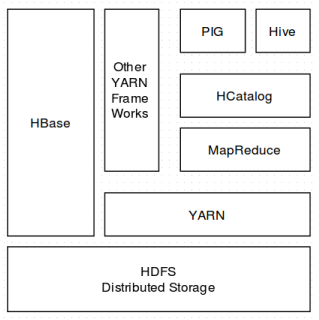

Services in Hadoop (2.x)
JobTracker is responsible for the Resource Manager. The fundamental idea of YARN is to split the two major responsibilities of the Job-Tracker – that is, resource management and job scheduling/monitoring—into separate daemons: a global ResourceManager and a per-application ApplicationMaster.
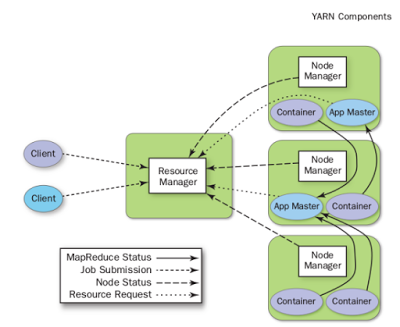
The NodeManager is the per-machine slave, which is responsible for launching the application’s containers, monitoring their resource usage (CPU, memory, disk, network), and reporting the same to the ResourceManager. The ResourceManager divides the resources among all the applications in the system. The ResourceManager has a pluggable scheduler component, which is responsible for allocating resources to the various running applications. The scheduler performs its scheduling function based on the resource requirements of an application by using the abstract notion of a resource container, which incorporates resource dimensions such as memory, CPU, disk, and network. The per-application ApplicationMaster is, performs negotiating for resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the component tasks.
Execution steps of YARN:
- Container executes a specific application
- Single NodeManager can have multiple numbers of containers
- After the container has been assigned to NodeManager, Resource Manager starts Application Master process within the container
- Perform computation required for the task
- In MapReduce Application Master process is mapper/reducer process
- If Application Master requires extra resources then Application Master running on Node Manager request to Resource Manager for additional resources, additional resources are in the form of containers
- Resource Manager scans the cluster and finds out free Node Manager
- Requested NodeManager don’t have info about the other free NodeManager
- Application Master on the original node starts off the Application Master on newly assigned nodes.
Various scheduler options
- FIFO Scheduler: Basically a simple “first come, first served” scheduler in which the Job-Tracker pulls jobs from a work queue, oldest job first.
- Capacity scheduler:-The Capacity scheduler is another pluggable scheduler for YARN that allows for multiple groups to securely share a large Hadoop cluster.
- Capacity is distributed among different queues.
- Each queue is allocated a share of the cluster resources
- A job can be submitted to the specific queue
- Within a queue, FIFO scheduling is used
- Default scheduler – Capacity Scheduler
- Fair scheduler:-Fair scheduling is a method of assigning resources to applications such that all applications get, on average, an equal share of resources over time
Configure scheduling policy:
$ vi yarn-site.xml <property> <name> yarn.resourcemanager.schedular.class </name> <value> org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler </value> </property>
We can define different queue for development and production
$ vi etc/hadoop/capacity-schedular.xml <property> <name>yarn.scheduler.capacity.root.queues</name> <value>dev, prod</value> <description>The queues at the this level (root is the root queue). </description> </property> <property> <name>yarn.scheduler.capacity.root.dev.capacity</name> <value>30</value> </property> <property> <name>yarn.scheduler.capacity.root.prod.capacity</name> <value>70</value> </property>
We can submit the job to the specific queue
$ hadoop jar sample.jar wordCount.Main -D mapreduce.job.queue.name=prod input output
You can check the queue at localhost:8088/cluster
