

Decision Tree Classifier for building a classification model using Python and Scikit
Decision Tree Classifier is a classification model that can be used for simple classification tasks where the data space is not huge and can be easily visualized. Despite being simple, it is showing very good results for simple tasks and outperforms other, more complicated models.

Article Overview:
- Decision Tree Classifier Dataset
- Decision Tree Classifier in Python with Scikit-Learn
- Decision Tree Classifier – preprocessing
- Training the Decision Tree Classifier model
- Using our Decision Tree model for predictions
- Decision Tree Visualisation
Decision Tree Classifier Dataset
Recently I’ve created a small dummy dataset to use for simple classification tasks. I’ll paste the dataset here again for your convenience.
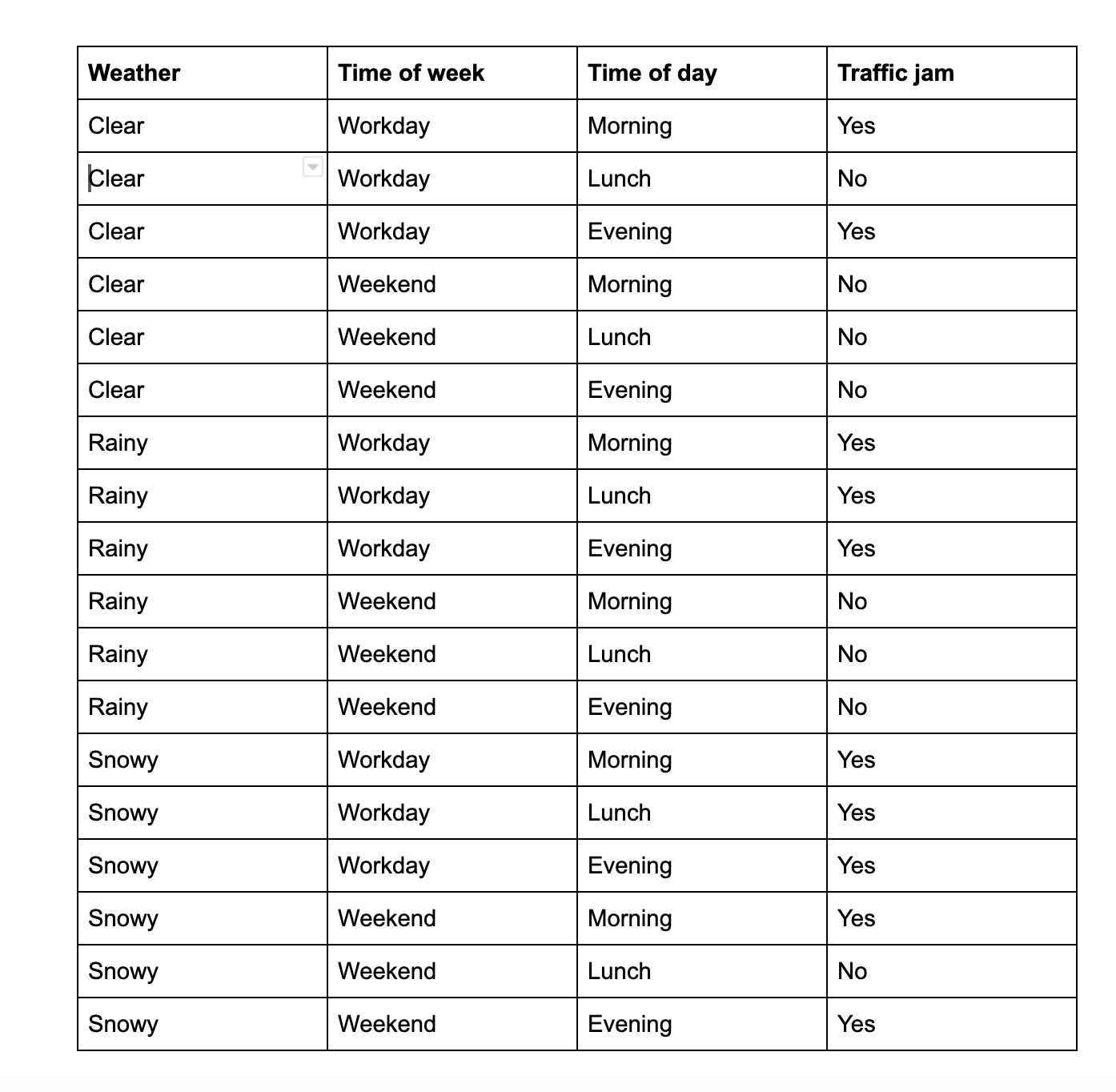
The purpose of this data is, given 3 facts about a certain moment(the weather, whether it is a weekend or a workday or whether it is morning, lunch or evening), can we predict if there’s a traffic jam in the city?
Decision Tree Classifier in Python with Scikit-Learn
We have 3 dependencies to install for this project, so let’s install them now. Obviously, the first thing we need is the scikit-learn library, and then we need 2 more dependencies which we’ll use for visualization.
pip3 install scikit-learn
pip3 install matplotlib
pip3 install pydotplus
Decision Tree Classifier – installing dependencies
Now let’s import what we need from these packages.
from sklearn import preprocessing
from sklearn import tree
from IPython.display import Image
import pydotplus
Decision Tree Classifier – importing dependencies
def getWeather():
return ['Clear', 'Clear', 'Clear', 'Clear', 'Clear', 'Clear',
'Rainy', 'Rainy', 'Rainy', 'Rainy', 'Rainy', 'Rainy',
'Snowy', 'Snowy', 'Snowy', 'Snowy', 'Snowy', 'Snowy']
def getTimeOfWeek():
return ['Workday', 'Workday', 'Workday',
'Weekend', 'Weekend', 'Weekend',
'Workday', 'Workday', 'Workday',
'Weekend', 'Weekend', 'Weekend',
'Workday', 'Workday', 'Workday',
'Weekend', 'Weekend', 'Weekend']
def getTimeOfDay():
return ['Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
]
def getTrafficJam():
return ['Yes', 'No', 'Yes',
'No', 'No', 'No',
'Yes', 'Yes', 'Yes',
'No', 'No', 'No',
'Yes', 'Yes', 'Yes',
'Yes', 'No', 'Yes'
]
Decision Tree Classifier – loading the data
Decision Tree Classifier – preprocessing
We know that computers have a really hard time when dealing with text and we can make their lives easier by converting the text to numerical values.
Label Encoder
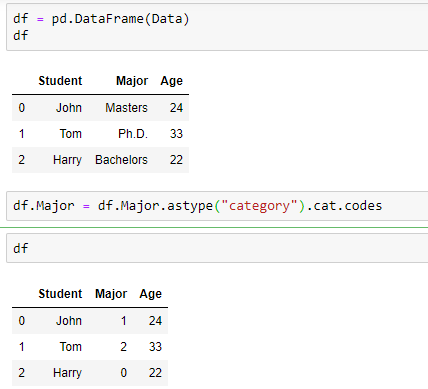
We will use this encoder provided by scikit to transform categorical data from text to numbers. If we have n possible values in our dataset, then LabelEncoder model will transform it into numbers from 0 to n-1 so that each textual value has a number representation.
For example, let’s encode our time of day values.
timeOfDay = ['Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
'Morning', 'Lunch', 'Evening',
]
labelEncoder = preprocessing.LabelEncoder()
encodedTimeOfDay = labelEncoder.fit_transform(timeOfDay)
print (encodedTimeOfDay)
# Prints [2 1 0 2 1 0 2 1 0 2 1 0 2 1 0 2 1 0]
Decision Tree Classifier – encoding our data
Training the Decision Tree Classifier model
Now let’s train our model. So remember, since all our features are textual values, we need to encode all our values and only then we can jump to training.
if __name__=="__main__":
# Get the data
weather = getWeather()
timeOfWeek = getTimeOfWeek()
timeOfDay = getTimeOfDay()
trafficJam = getTrafficJam()
labelEncoder = preprocessing.LabelEncoder()
# Encode the features and the labels
encodedWeather = labelEncoder.fit_transform(weather)
encodedTimeOfWeek = labelEncoder.fit_transform(timeOfWeek)
encodedTimeOfDay = labelEncoder.fit_transform(timeOfDay)
encodedTrafficJam = labelEncoder.fit_transform(trafficJam)
# Build the features
features = []
for i in range(len(encodedWeather)):
features.append([encodedWeather[i], encodedTimeOfWeek[i], encodedTimeOfDay[i]])
classifier = tree.DecisionTreeClassifier()
classifier = classifier.fit(features, encodedTrafficJam)
Decision Tree Classifier – training our model
Using our Decision Tree model for predictions
Now we can use the model we have trained to make predictions about the traffic jam.
# ["Snowy", "Workday", "Morning"]
print(classifier.predict([[2, 1, 2]]))
# Prints [1], meaning "Yes"
# ["Clear", "Weekend", "Lunch"]
print(classifier.predict([[0, 0, 1]]))
# Prints [0], meaning "No"
Decision Tree Classifier – making predictions
And it seems to be working! It correctly predicts the traffic jam situations given our data.
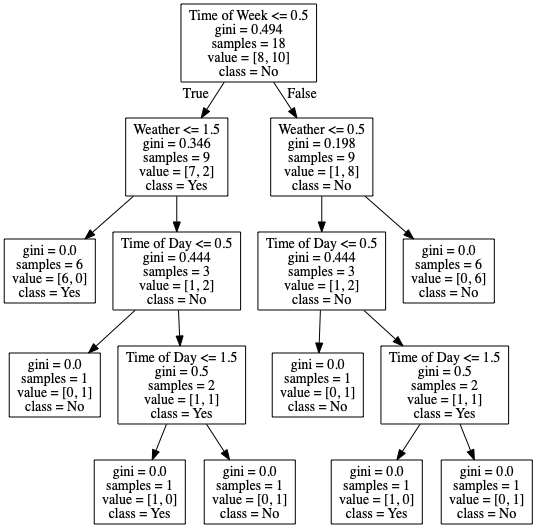
Decision Tree Visualisation
Scikit also provides us with a way of visualizing a Decision Tree model. Here’s a quick helper method I wrote to generate a png image from our decision tree.
def printTree(classifier):
feature_names = ['Weather', 'Time of Week', 'Time of Day']
target_names = ['Yes', 'No']
# Build the daya
dot_data = tree.export_graphviz(classifier, out_file=None,
feature_names=feature_names,
class_names=target_names)
# Build the graph
graph = pydotplus.graph_from_dot_data(dot_data)
# Show the image
Image(graph.create_png())
graph.write_png("tree.png")
Decision Tree Classifier – visualizing the decision tree
And here’s the result from that.































































{kind=link}